Concepts¶
Overview¶
Tornado is a high performance, scalable application, and is intended to handle millions of events each second on standard server hardware. Its overall architecture is depicted in Tornado architecture.
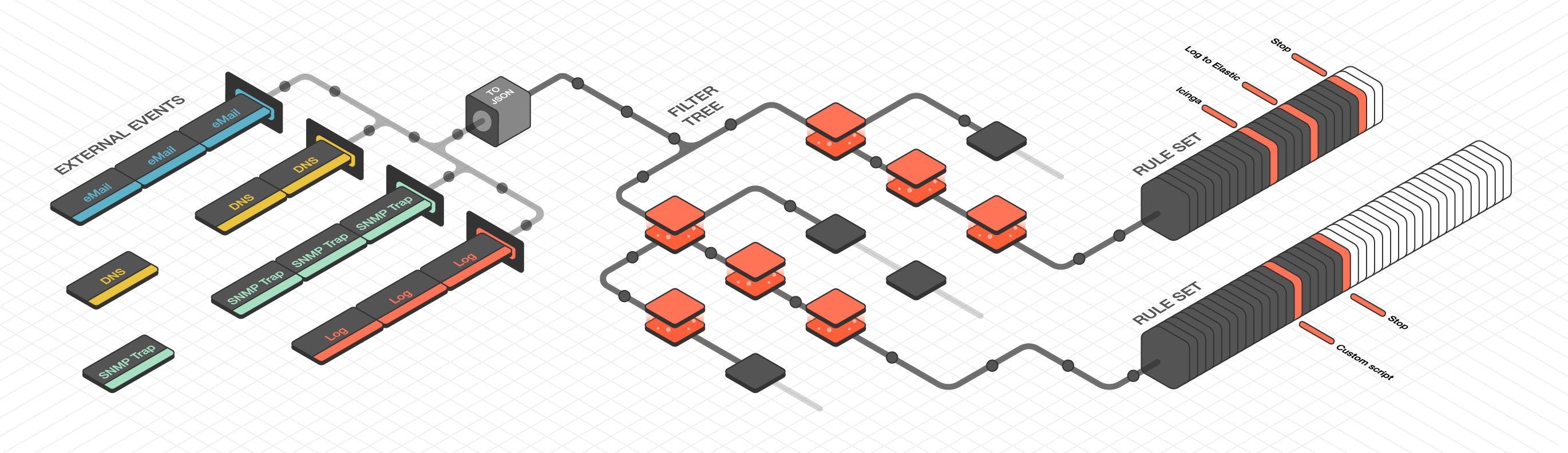
Fig. 152 Tornado architecture¶
Tornado Architecture¶
Tornado is structured as a library, and there are three main components of its architecture:
The Tornado Collector(s), or just Collector(s)
The Tornado Engine, or Engine
The Tornado Executor(s), or Executor(s)*
The term Tornado refers to the whole project or to a deployed system that includes all three components.
Architecturally, Tornado is organized as a processing pipeline, where input events move from Collectors to the Engine, to Executors, without branching or returning.
When the system receives an External Event, it first arrives at a Collector where it is converted into a Tornado Event. Then it is forwarded to the Tornado Engine where it is matched against user-defined, composable Rules. Finally, generated Actions are dispatched to the Executors.
Collectors¶
The purpose of a Collector is to receive and convert external events into the internal Tornado Event structure, and forward them to the Tornado Engine.
Collectors are Datasource-specific. For each datasource, there must be at least one Collector that knows how to manipulate the datasource’s Events and generate Tornado Events.
Out of the box, Tornado provides a number of Collectors for handling inputs from snmptrapd, rsyslog, JSON from Nats channels and generic Webhooks. All the collectors are pre-configured on NetEye, however, there are some that may eventually be configured manually in order to fit your purposes, e.g. Tornado Webhook or Icinga 2 Collectors.
See also
More details on Tornado Collectors and how they can be configured can be found in Tornado Collectors.
Tornado Collectors run on the NetEye Master and on Satellites if there are any. A Satellite converts an event into JSON and sends it to the Master with Tornado Nats JSON Collector.
Engine¶
The Engine is the second step of the pipeline. It receives and processes the events produced by the Collectors. The outcome of this step is fully defined by a processing tree composed of Filters and Rule Sets.
A Filter is a processing node that defines an access condition on the children nodes.
A Rule Set is a node that contains an ordered set of Rules, where each Rule determines:
The conditions a Tornado Event has to respect to match it
The actions to be executed in case of a match
The processing tree is parsed at startup from a configuration folder where the node definitions are stored in JSON format.
When an event matches one or more Rules, the Engine produces a set of Actions and forwards them to one or more Executors.
Executors¶
The Executors are the last element in the Tornado pipeline. They receive the Actions produced from the Engine and trigger the associated executable instructions.
An Action can be any command, process or operation. For example it can include:
Forwarding the events to a monitoring system
Logging events locally (e.g., as processed, discarded or matched) or remotely
Archiving events using software such as the Elastic Stack
Invoking a custom shell script
A single Executor usually takes care of a single Action type.
More information and example code snippets can be found in Section Tornado Actions.
Multitenancy¶
Tornado can be run on both single-tenant and multi-tenant environments. In case of a multi-tenant environment, each tenant has only got access to the part of a processing tree (starting from a filter) that contains filtered events received from this particular tenant. This way all the event streams are processed independently and securely.