Configuration¶
Access to Icinga Web 2¶
When Tornado is installed, NetEye creates an Icinga Web 2 user
neteye-tornado and an associated Icinga Web 2 role
neteye_tornado_director_apis, which only gives access to the module
Director, with limited authorizations on the actions that Tornado can
perform.
Warning
These user and permission are required by the backend, for Tornado to call the Director API–and in particular for the authentication and authorization of the Tornado Director Executor to the APIs of the Icinga Director. Therefore neither the user, nor the associated role must be removed from the system.
In case you need it, for example to reconfigure the Tornado Director
Executor, the password for the user neteye-tornado is stored in the
file /root/.pwd_icingaweb2_neteye_tornado.
Import and Export Configuration¶
The Tornado GUI provides multiple ways to import and export the whole configuration or just a subset of it.
Export Configuration¶
You have three possibilities to export Tornado configuration or part of it:
entire configuration: select the root node from the Processing Tree View and click on the export button to download the entire configuration
a node (either a ruleset or a filter): select the node from the Processing Tree View and click on the export button to download the node and its sub-nodes
a single rule: navigate to the rules table, select a rule, and click on the export button
Hint
You can backup and download Tornado configuration by exporting the entire configuration.
Import Configuration¶
You can use the import feature to upload to NetEye a previously downloaded configuration, new custom rules, or even the configuration from another NetEye instance.
When clicking on the import button a popup will appear with the following fields:
Node File: the file containing the configuration
Note
When importing a single rule the field will be labeled as Rule File.
Replace whole configuration?: If selected, the imported configuration will replace the root node and all of its sub-nodes.
Hint
You can restore a previous Tornado configuration by selecting this option.
Parent Node: The parent node where to add the imported configuration, by default it is set to the currently selected node.
Note
When a node or a rule with the same name of an already existing one is imported, the name of the new node/rule will be suffixed with _imported.
Tornado Collectors Configuration¶
JMESPath Collector Configuration¶
The Collector configuration is composed of two named values:
event_type: Identifies the type of Event, and can be a String or a JMESPath expression (see below).
payload: A Map<String, ValueProcessor> with event-specific data.
and here the payload ValueProcessor can be one of:
A null value
A string
A bool value (i.e., true or false)
A number
An array of values
A map of type Map<String, ValueProcessor>
A JMESPath expression : A valid JMESPath expression delimited by the ‘${’ and ‘}’ characters.
The Collector configuration defines the structure of the Event produced. The configuration’s event_type property will define the type of Event, while the Event’s payload will have the same structure as the configuration’s payload.
How it Works
The JMESPath expressions of the configuration will be applied to incoming inputs, and the results will be included in the Event produced. All other ValueProcessors, instead, are copied without modification.
For example, consider the following configuration:
{
"event_type": "webhook",
"payload": {
"name" : "${reference.authors[0]}",
"from": "jmespath-collector",
"active": true
}
}
The value ${reference.authors[0]} is a JMESPath expression, delimited
by ${ and }, and whose value depends on the incoming input.
Thus if this input is received:
{
"date": "today",
"reference": {
"authors" : [
"Francesco",
"Thomas"
]
}
}
then the Collector will produce this Event:
{
"event_type": "webhook",
"payload": {
"name" : "Francesco",
"from": "jmespath-collector",
"active": true
}
}
Runtime behavior
When the JMESPath expression returns an array or a map, the entire object will be inserted as-is into the Event.
However, if a JMESPath expression does not return a valid result, then no Event is created, and an error is produced.
Email Collector Configuration¶
The executable configuration is based partially on configuration files, and partially on command line parameters.
The available startup parameters are:
config-dir: The filesystem folder from which the Collector configuration is read. The default path is /etc/tornado_email_collector/.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/email_collector.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
email_collector:
tornado_event_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events. If present, this value overrides what specified by the
tornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.tornado_event_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events. This entry is mandatory if
tornado_connection_channelis set toTCP. If present, this value overrides what specified by thetornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.message_queue_size: The in-memory buffer size for Events. It makes the application resilient to Tornado Engine crashes or temporary unavailability. When Tornado restarts, all messages in the buffer will be sent. When the buffer is full, the Collector will start discarding older messages first.
uds_path: The Unix Socket path on which the Collector will listen for incoming emails.
tornado_connection_channel: The channel to send events to Tornado. It contains the set of entries required to configure a Nats or a TCP connection. Beware that this entry will be taken into account only if ``tornado_event_socket_ip`` and ``tornado_event_socket_port`` are not provided.
In case of connection using Nats, these entries are mandatory:
nats.client.addresses: The addresses of the NATS server.
nats.client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats.client.auth.path_to_pkcs12_bundle: The path to a PKCS12 file that will be used for authenticating to NATS (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.pkcs12_bundle_password: The password to decrypt the provided PKCS12 file (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats.client.auth.typeis set toTls).nats.subject: The NATS Subject where tornado will subscribe and listen for incoming events.
In case of connection using TCP, these entries are mandatory:
tcp_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events.
tcp_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events.
More information about the logger configuration is available in the Common Logger documentation.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_EMAIL_COLLECTOR_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_EMAIL_COLLECTOR_CONFIG_DIR_DEFAULT=/my/custom/path cargo
build
An example of a full startup command is:
./tornado_email_collector \
--config-dir=/tornado-email-collector/config \
In this example the Email Collector starts up and then reads the configuration from the /tornado-email-collector/config directory.
Tornado Rsyslog Collector Configuration¶
The executable configuration is based partially on configuration files, and partially on command line parameters.
The available startup parameters are:
config-dir: The filesystem folder from which the Collector configuration is read. The default path is /etc/tornado_rsyslog_collector/.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/rsyslog_collector.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
rsyslog_collector:
tornado_event_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events. If present, this value overrides what specified by the
tornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.tornado_event_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events. This entry is mandatory if
tornado_connection_channelis set toTCP. If present, this value overrides what specified by thetornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.message_queue_size: The in-memory buffer size for Events. It makes the application resilient to Tornado Engine crashes or temporary unavailability. When Tornado restarts, all messages in the buffer will be sent. When the buffer is full, the Collector will start discarding older messages first.
tornado_connection_channel: The channel to send events to Tornado. It contains the set of entries required to configure a Nats or a TCP connection. Beware that this entry will be taken into account only if ``tornado_event_socket_ip`` and ``tornado_event_socket_port`` are not provided.
In case of connection using Nats, these entries are mandatory:
nats.client.addresses: The addresses of the NATS server.
nats.client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats.client.auth.path_to_pkcs12_bundle: The path to a PKCS12 file that will be used for authenticating to NATS (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.pkcs12_bundle_password: The password to decrypt the provided PKCS12 file (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats.client.auth.typeis set toTls).nats.subject: The NATS Subject where tornado will subscribe and listen for incoming events.
In case of connection using TCP, these entries are mandatory:
tcp_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events.
tcp_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events.
More information about the logger configuration is available in the Common Logger documentation.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_RSYSLOG_COLLECTOR_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_RSYSLOG_COLLECTOR_CONFIG_DIR_DEFAULT=/my/custom/path cargo build
Tornado Webhook Collector Configuration¶
The executable configuration is based partially on configuration files, and partially on command line parameters.
The available startup parameters are:
config-dir: The filesystem folder from which the Collector configuration is read. The default path is /etc/tornado_webhook_collector/.
webhooks-dir: The folder where the Webhook configurations are saved in JSON format; this folder is relative to the
config_dir. The default value is /webhooks/.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/webhook_collector.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
webhook_collector:
tornado_event_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events. If present, this value overrides what specified by the
tornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.tornado_event_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events. This entry is mandatory if
tornado_connection_channelis set toTCP. If present, this value overrides what specified by thetornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.message_queue_size: The in-memory buffer size for Events. It makes the application resilient to errors or temporary unavailability of the Tornado connection channel. When the connection on the channel is restored, all messages in the buffer will be sent. When the buffer is full, the Collector will start discarding older messages first.
server_bind_address: The IP to bind the HTTP server to.
server_port: The port to be used by the HTTP Server.
tornado_connection_channel: The channel to send events to Tornado. It contains the set of entries required to configure a Nats or a TCP connection. Beware that this entry will be taken into account only if ``tornado_event_socket_ip`` and ``tornado_event_socket_port`` are not provided.
In case of connection using Nats, these entries are mandatory:
nats.client.addresses: The addresses of the NATS server.
nats.client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats.client.auth.path_to_pkcs12_bundle: The path to a PKCS12 file that will be used for authenticating to NATS (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.pkcs12_bundle_password: The password to decrypt the provided PKCS12 file (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats.client.auth.typeis set toTls).nats.subject: The NATS Subject where tornado will subscribe and listen for incoming events.
In case of connection using TCP, these entries are mandatory:
tcp_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events.
tcp_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events.
More information about the logger configuration can be found in the Common Logger documentation.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_WEBHOOK_COLLECTOR_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_WEBHOOK_COLLECTOR_CONFIG_DIR_DEFAULT=/my/custom/path cargo build
An example of a full startup command is:
./tornado_webhook_collector \
--config-dir=/tornado-webhook-collector/config
In this example the Webhook Collector starts up and then reads the configuration from the /tornado-webhook-collector/config directory.
Webhooks Configuration
As described before, the two startup parameters config-dir and webhooks-dir determine the path to the Webhook configurations, and each webhook is configured by providing id, token and collector_config.
As an example, consider how to configure a webhook for a repository hosted on Github.
If we start the application using the command line provided in the previous section, the webhook configuration files should be located in the /tornado-webhook-collector/config/webhooks directory. Each configuration is saved in a separate file in that directory in JSON format (the order shown in the directory is not necessarily the order in which the hooks are processed):
/tornado-webhook-collector/config/webhooks
|- github.json
|- bitbucket_first_repository.json
|- bitbucket_second_repository.json
|- ...
An example of valid content for a Webhook configuration JSON file is:
{
"id": "github_repository",
"token": "secret_token",
"collector_config": {
"event_type": "${commits[0].committer.name}",
"payload": {
"source": "github",
"ref": "${ref}",
"repository_name": "${repository.name}"
}
}
}
This configuration assumes that this endpoint has been created:
http(s)://collector_ip:collector_port/event/github_repository
However, the Github webhook issuer must pass the token at each call. Consequently, the actual URL to be called will have this structure:
http(s)://collector_ip:collector_port/event/github_repository?token=secret_token
Security warning: Since the security token is present in the query string, it is extremely important that the webhook Collector is always deployed with HTTPS in production. Otherwise, the token will be sent unencrypted along with the entire URL.
Consequently, if the public IP of the Collector is, for example, 35.35.35.35 and the server port is 1234, in Github, the webhook settings page should look like in Fig. 158.
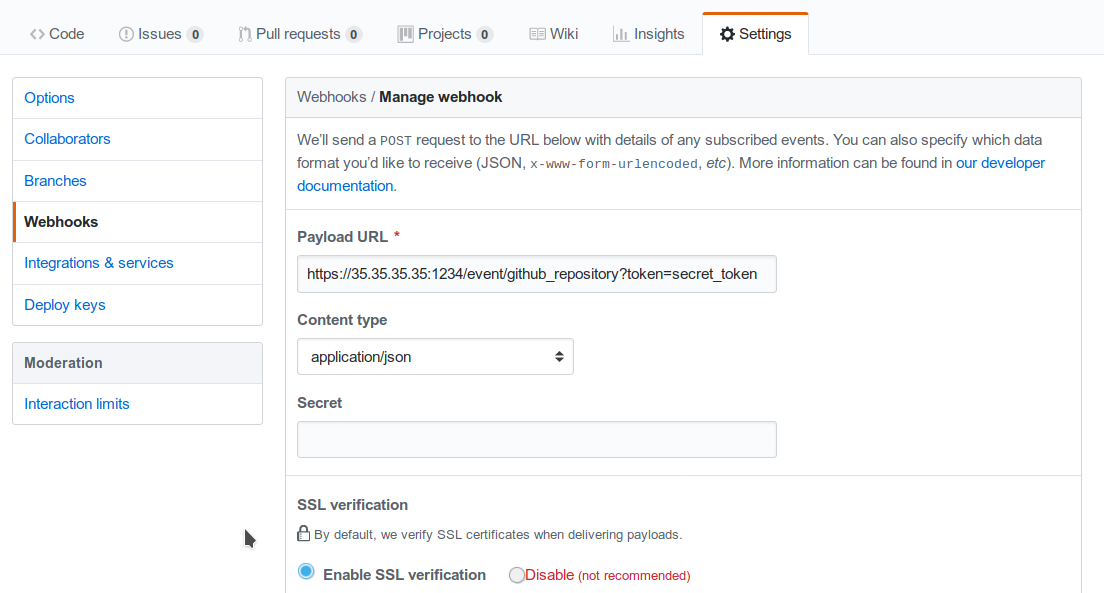
Fig. 158 Configuring a GitHub webhook.¶
Finally, the collector_config configuration entry determines the content of the tornado Event associated with each webhook input.
So for example, if Github sends this JSON (only the relevant parts shown here):
{
"ref": "refs/heads/master",
"commits": [
{
"id": "33ad3a6df86748011ee8d5cef13d206322abc68e",
"committer": {
"name": "GitHub",
"email": "noreply@github.com",
"username": "web-flow"
}
}
],
"repository": {
"id": 123456789,
"name": "webhook-test"
}
}
then the resulting Event will be:
{
"type": "GitHub",
"created_ms": 1554130814854,
"payload": {
"source": "github",
"ref": "refs/heads/master",
"repository_name": "webhook-test"
}
}
The Event creation logic is handled internally by the JMESPath collector, a detailed description of which is available in its specific documentation.
Tornado Nats JSON Collector Configuration¶
The executable configuration is based partially on configuration files, and partially on command line parameters.
The available startup parameters are:
config-dir: The filesystem folder from which the Collector configuration is read. The default path is /etc/tornado_nats_json_collector/.
topics-dir: The folder where the topic configurations are saved in JSON format; this folder is relative to the
config_dir. The default value is /topics/.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/nats_json_collector.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
nats_json_collector:
message_queue_size: The in-memory buffer size for Events. It makes the application resilient to errors or temporary unavailability of the Tornado connection channel. When the connection on the channel is restored, all messages in the buffer will be sent. When the buffer is full, the Collector will start discarding older messages first.
nats_client.addresses: The addresses of the NATS server.
nats_client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats_client.auth.path_to_pkcs12_bundle: The path to a PKCS12 file that will be used for authenticating to NATS (Mandatory if
nats_client.auth.typeis set toTls).nats_client.auth.pkcs12_bundle_password: The password to decrypt the provided PKCS12 file (Mandatory if
nats_client.auth.typeis set toTls).nats_client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats_client.auth.typeis set toTls).tornado_connection_channel: The channel to send events to Tornado. It contains the set of entries required to configure a Nats or a TCP connection.
In case of connection using Nats, these entries are mandatory:
nats_subject: The NATS Subject where tornado will subscribe and listen for incoming events.
In case of connection using TCP, these entries are mandatory:
tcp_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events.
tcp_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events.
More information about the logger configurationis available in the Common Logger documentation.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_NATS_JSON_COLLECTOR_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_NATS_JSON_COLLECTOR_CONFIG_DIR_DEFAULT=/my/custom/path cargo build
An example of a full startup command is:
./tornado_nats_json_collector \
--config-dir=/tornado-nats-json-collector/config
In this example the Nats JSON Collector starts up and then reads the configuration from the /tornado-nats-json-collector/config directory.
Topics Configuration
As described before, the two startup parameters config-dir and topics-dir determine the path to the topic configurations, and each topic is configured by providing nats_topics and collector_config.
As an example, consider how to configure a “simple_test” topic.
If we start the application using the command line provided in the previous section, the topics configuration files should be located in the /tornado-nats-json-collector/config/topics directory. Each configuration is saved in a separate file in that directory in JSON format (the order shown in the directory is not necessarily the order in which the topics are processed):
/tornado-nats-json-collector/config/topics
|- simple_test.json
|- something_else.json
|- ...
An example of valid content for a Topic configuration JSON file is:
{
"nats_topics": ["simple_test_one", "simple_test_two"],
"collector_config": {
"event_type": "${content.type}",
"payload": {
"ref": "${content.ref}",
"repository_name": "${repository}"
}
}
}
With this configuration, two subscriptions are created to the Nats topics simple_test_one and simple_test_two. Messages received by those topics are processed using the collector_config that determines the content of the tornado Event associated with them.
It is important to note that, if a Nats topic name is used more than once, then the Collector will perfom multiple subscriptions accordingly. This can happen if a topic name is duplicated into the nats_topics array or in multiple JSON files.
So for example, if this JSON message is received:
{
"content": {
"type": "content_type",
"ref": "refs/heads/master"
},
"repository": {
"id": 123456789,
"name": "webhook-test"
}
}
then the resulting Event will be:
{
"type": "content_type",
"created_ms": 1554130814854,
"payload": {
"ref": "refs/heads/master",
"repository": {
"id": 123456789,
"name": "webhook-test"
}
}
}
The Event creation logic is handled internally by the JMESPath collector, a detailed description of which is available in its specific documentation.
Default values
The collector_config section and all of its internal entries are optional. If not provided explicitly, the Collector will use these predefined values:
When the collector_config.event_type is not provided, the name of the Nats topic that sent the message is used as Event type.
When the collector_config.payload is not provided, the entire source message is included in the payload of the generated Event with the key data.
Consequently, the simplest valid topic configuration contains only the nats_topics:
{
"nats_topics": ["subject_one", "subject_two"]
}
The above one is equivalent to:
{
"nats_topics": ["subject_one", "subject_two"],
"collector_config": {
"payload": {
"data": "${@}"
}
}
}
In this case the generated Tornado Events have type equals to the topic name and the whole source data in their payload.
Tornado Icinga 2 Collector Configuration¶
The executable configuration is based partially on configuration files, and partially on command line parameters.
The available startup parameters are:
config-dir: The filesystem folder from which the Collector configuration is read. The default path is /etc/tornado_icinga2_collector/.
streams_dir: The folder where the Stream configurations are saved in JSON format; this folder is relative to the
config_dir. The default value is /streams/.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/icinga2_collector.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
icinga2_collector
tornado_event_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events. If present, this value overrides what specified by the
tornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.tornado_event_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events. This entry is mandatory if
tornado_connection_channelis set toTCP. If present, this value overrides what specified by thetornado_connection_channelentry. This entry is deprecated and will be removed in the next release of tornado. Please, use the ``tornado_connection_channel`` instead.message_queue_size: The in-memory buffer size for Events. It makes the application resilient to Tornado Engine crashes or temporary unavailability. When Tornado restarts, all messages in the buffer will be sent. When the buffer is full, the Collector will start discarding older messages first.
connection
server_api_url: The complete URL of the Icinga 2 Event Stream API.
username: The username used to connect to the Icinga 2 APIs.
password: The password used to connect to the Icinga 2 APIs.
disable_ssl_verification: A boolean value. If true, the client will not verify the Icinga 2 SSL certificate.
sleep_ms_between_connection_attempts: In case of connection failure, the number of milliseconds to wait before a new connection attempt.
tornado_connection_channel: The channel to send events to Tornado. It contains the set of entries required to configure a Nats or a TCP connection. Beware that this entry will be taken into account only if ``tornado_event_socket_ip`` and ``tornado_event_socket_port`` are not provided.
In case of connection using Nats, these entries are mandatory:
nats.client.addresses: The addresses of the NATS server.
nats.client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats.client.auth.path_to_pkcs12_bundle: The path to a PKCS12 file that will be used for authenticating to NATS (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.pkcs12_bundle_password: The password to decrypt the provided PKCS12 file (Mandatory if
nats.client.auth.typeis set toTls).nats.client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats.client.auth.typeis set toTls).nats.subject: The NATS Subject where tornado will subscribe and listen for incoming events.
In case of connection using TCP, these entries are mandatory:
tcp_socket_ip: The IP address where outgoing events will be written. This should be the address where the Tornado Engine listens for incoming events.
tcp_socket_port: The port where outgoing events will be written. This should be the port where the Tornado Engine listens for incoming events.
More information about the logger configuration is available in the Common Logger documentation.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_ICINGA2_COLLECTOR_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_ICINGA2_COLLECTOR_CONFIG_DIR_DEFAULT=/my/custom/path cargo
build
An example of a full startup command is:
./tornado_webhook_collector \
--config-dir=/tornado-icinga2-collector/config
In this example the Icinga 2 Collector starts up and then reads the configuration from the /tornado-icinga2-collector/config directory.
Streams Configuration
As described before, the two startup parameters config-dir and streams-dir determine the path to the stream configurations.
For example, if we start the application using the command line provided in the previous section, the stream configuration files should be located in the /tornado-icinga2-collector/config/streams directory. Each configuration is saved in a separate file in that directory in JSON format:
/tornado-icinga2-collector/config/streams
|- 001_CheckResults.json
|- 002_Notifications.json
|- ...
The alphabetical ordering of the files has no impaact on the Collector’s logic.
An example of valid content for a stream configuration JSON file is:
{
"stream": {
"types": ["CheckResult"],
"queue": "icinga2_CheckResult",
"filter": "event.check_result.exit_status==2"
},
"collector_config": {
"event_type": "icinga2_event",
"payload": {
"source": "icinga2",
"icinga2_event": "${@}"
}
}
}
This stream subscription will receive all Icinga 2 Events of type ‘CheckResult’ with ‘exit_status’=2. It will then produce a Tornado Event with type ‘icinga2_event’ and the entire Icinga 2 Event in the payload with key ‘icinga2_event’.
The Event creation logic is handled internally by the JMESPath collector, a detailed description of which is available in its specific documentation.
SNMPTrapd TCP Collector Configuration¶
Prerequisites
This Collector has the following runtime requirements:
Perl 5.16 or greater
Perl packages required:
Cpanel::JSON::XS
NetSNMP::TrapReceiver
You can verify that the Perl packages are available with the command:
$ perl -e 'use Cpanel::JSON::XS;' && \
perl -e 'use NetSNMP::TrapReceiver;'
If no messages are displayed in the console, then everything is okay; otherwise, you will see error messages.
In case of missing dependencies, use your system’s package manager to install them.
For example, the required Perl packages can be installed on an Ubuntu system with:
$ sudo apt install libcpanel-json-xs-perl libsnmp-perl
Activation
This Collector is meant to be integrated with snmptrapd. To activate it, put the following line in your snmptrapd.conf file:
perl do "/path_to_the_script/snmptrapd_tcp_collector.pl";
Consequently, it is never started manually, but instead will be started, and managed, directly by snmptrapd itself.
At startup, if the Collector is configured properly, you should see this entry either in the logs or in the daemon’s standard error output:
The TCP based snmptrapd_collector was loaded successfully.
Configuration options
The address of the Tornado Engine TCP instance to which the events are forwarded is configured with the following environment variables:
TORNADO_ADDR: the IP address of Tornado Engine. If not specified, it will use the default value 127.0.0.1
TORNADO_PORT: the port of the TCP socket of Tornado Engine. If not specified, it will use the default value 4747
SNMPTrapd NATS Collector Configuration¶
Prerequisites
This Collector has the following runtime requirements:
Perl 5.16 or greater
Perl packages required:
Cpanel::JSON::XS
Net::NATS::Client
NetSNMP::TrapReceiver
You can verify that the Perl packages are available with the command:
$ perl -e 'use Cpanel::JSON::XS;' && \
perl -e 'use Net::NATS::Client;' && \
perl -e 'use NetSNMP::TrapReceiver;'
If no messages are displayed in the console, then everything is okay; otherwise, you will see error messages.
In case of missing dependencies, use your system’s package manager to install them.
Instructions for installing Net::NATS::Client are available at its
official repository
Activation
This Collector is meant to be integrated with snmptrapd. To activate it, put the following line in your snmptrapd.conf file:
perl do "/path_to_the_script/snmptrapd_collector.pl";
Consequently, it is never started manually, but instead will be started, and managed, directly by snmptrapd itself.
At startup, if the Collector is configured properly, you should see this entry either in the logs or in the daemon’s standard error output:
The snmptrapd_collector for NATS was loaded successfully.
Configuration options
The information to connect to the NATS Server are provided by the following environment variables:
TORNADO_NATS_ADDR: the address of the NATS server. If not specified, it will use the default value 127.0.0.1:4222
TORNADO_NATS_SUBJECT: the NATS subject where the events are published. If not specified, it will use the default value tornado.events
TORNADO_NATS_SSL_CERT_PEM_FILE: The filesystem path of a PEM certificate. This entry is optional, when provided, the Collector will use the certificate to connect to the NATS server
TORNADO_NATS_SSL_CERT_KEY: The filesystem path for the KEY of the PEM certificate provided by the TORNADO_NATS_SSL_CERT_PEM_FILE entry. This entry is mandatory if the TORNADO_NATS_SSL_CERT_PEM_FILE entry is provided
Tornado Engine CLI Commands and Configuration¶
The Tornado CLI has commands that allow you to use the functionality provided. Running the Tornado executable without any arguments returns a list of all available commands and global options that apply to every command.
Tornado commands:
apm-tracing enable|disable: Enable or disable the APM priority logger output.When used with enable, it:
enables the APM logger
disables the stdout logger output
sets logger level to info,tornado=debug
When used with disable, it:
disables the APM logger
enables the stdout logger output
sets logger level to value from the configuration file
check : Checks that the configuration is valid.
daemon : Starts the Tornado daemon.
help : Prints the general help page, or the specific help of the given command.
rules-upgrade : Checks the current configuration and, if available, upgrades the rules structure to the most recent one.
filter-create : Creates a Filter at the root level of the current configuration and of the open drafts.
Parameters:
name: The name of the Filter to be created.
json-definition: The JSON representation of the Filter.
In case a Node with the same name already exists at the root level of the configuration, the following will happen:
If the existing node is a Ruleset, it will be renamed to: <ruleset_name>_backup_<timestamp_in_milliseconds>.
If the existing node is a Filter having a different filter definition, it will be renamed to: <filter_name>_backup_<timestamp_in_milliseconds>.
If the existing node is a Filter having the same filter definition, nothing will be done.
Each CLI command provides its own help and usage information, you can
display using the help command.
For example, with this command you can show the help page and options of
daemon:
./tornado_engine help daemon
The Tornado configuration is partly based on configuration files and partly based on command line parameters. The location of configuration files in the file system is determined at startup based on the provided CLI options.
Tornado global options:
config-dir: The filesystem folder from which the Tornado configuration is read. The default path is /etc/tornado.
rules-dir: The folder where the Rules are saved in JSON format; this folder is relative to
config_dir. The default value is /rules.d/.
The check command does not have any specific options.
The daemon command has options specified in the tornado.daemon section of the tornado.toml configuration file.
In addition to these parameters, the following configuration entries are available in the file ‘config-dir’/tornado.toml:
logger:
level: The Logger level; valid values are trace, debug, info, warn, and error.
stdout: Determines whether the Logger should print to standard output. Valid values are
trueandfalse.file_output_path: A file path in the file system; if provided, the Logger will append any output to it.
tornado.daemon
thread_pool_config: The configuration of the thread pools bound to the internal queues. This entry is optional and should be rarely configured manually. For more details see the following Structure and Configuration: The Thread Pool Configuration section.
retry_strategy.retry_policy: The global retry policy for reprocessing failed actions. (Optional. Defaults to
MaxAttemptsif not provided). For more details see the following Structure and Configuration: Retry Strategy Configuration section.retry_strategy.backoff_policy: The global back-off policy for reprocessing failed actions. (Mandatory only if
retry_strategy.retry_policyis provided). For more details see the following Structure and Configuration: Retry Strategy Configuration section.event_tcp_socket_enabled: Whether to enable the TCP server for incoming events (Optional. Valid values are
trueandfalse. Defaults totrueif not provided).event_socket_ip: The IP address where Tornado will listen for incoming events (Mandatory if
event_tcp_socket_enabledis set to true).event_socket_port: The port where Tornado will listen for incoming events (Mandatory if
event_tcp_socket_enabledis set to true).nats_enabled: Whether to connect to the NATS server (Optional. Valid values are
trueandfalse. Defaults tofalseif not provided).nats_extractors: List of data extractors for incoming Nats messages (Optional). Valid extractors are:
FromSubject: using a regex, extracts the first matching group from the Nats subject and adds its value to the event.metadata scope using the specified key. Example:
nats_extractors = [ { type = "FromSubject", key = "tenant_id", regex = "^([^.]+)\\.tornado\\.events" } ]
nats.client.addresses: Array of addresses of the NATS nodes of a cluster. (Mandatory if
nats_enabledis set to true).nats.subject: The NATS Subject where tornado will subscribe and listen for incoming events (Mandatory if
nats_enabledis set to true).nats.client.auth.type: The type of authentication used to authenticate to NATS (Optional. Valid values are
NoneandTls. Defaults toNoneif not provided).nats.client.auth.certificate_path: The path to the client certificate that will be used for authenticating to NATS. (Mandatory if nats.client.auth.type is set to Tls).
nats.client.auth.private_key_path: The path to the client certificate private key that will be used for authenticating to NATS. (Mandatory if nats.client.auth.type is set to Tls).
nats.client.auth.path_to_root_certificate: The path to a root certificate (in
.pemformat) to trust in addition to system’s trust root. May be useful if the NATS server is not trusted by the system as default. (Optional, valid ifnats.client.auth.typeis set toTls).web_server_ip: The IP address where the Tornado Web Server will listen for HTTP requests. This is used, for example, by the monitoring endpoints.
web_server_port: The port where the Tornado Web Server will listen for HTTP requests.
web_max_json_payload_size: The max JSON size in bytes accepted by a Tornado endpoint. (Optional. Defaults to 67108860 (i.e. 64MB))
More information about the logger configuration is available in section Common Logger.
The default config-dir value can be customized at build time by specifying the environment variable TORNADO_CONFIG_DIR_DEFAULT. For example, this will build an executable that uses /my/custom/path as the default value:
TORNADO_CONFIG_DIR_DEFAULT=/my/custom/path cargo build
The command-specific options should always be used after the command name, while the global ones always precede it. An example of a full startup command is:
./tornado_engine
--config-dir=./tornado/engine/config \
daemon
In this case, the CLI executes the daemon command that starts the Engine with the configuration read from the ./tornado/engine/config directory. In addition, it will search for Filter and Rule definitions in the ./tornado/engine/config/rules.d directory in order to build the processing tree.
Structure and Configuration: The Thread Pool Configuration¶
Even if the default configuration should suit most of the use cases, in some particular situations it could be useful to customise the size of the internal queues used by Tornado. Tornado utilizes these queues to process incoming events and to dispatch triggered actions.
Tornado uses a dedicated thread pool per queue; the size of each queue is by default equal to the number of available logical CPUs. Consequently, in case of an action of type script, for example, Tornado will be able to run in parallel at max as many scripts as the number of CPUs.
This default behaviour can be overridden by providing a custom configuration for the thread pools size. This is achieved through the optional tornado_pool_config entry in the tornado.daemon section of the Tornado.toml configuration file.
Example of Thread Pool’s Dynamical Configuration¶
[tornado.daemon]
thread_pool_config = {type = "CPU", factor = 1.0}
In this case, the size of the thread pool will be equal to
(number of available logical CPUs) multiplied by (factor) rounded to
the smallest integer greater than or equal to a number. If the resulting
value is less than 1, then 1 will be used be default.
For example, if there are 16 available CPUs, then:
{type: "CPU", factor: 0.5}=> thread pool size is 8{type: "CPU", factor: 2.0}=> thread pool size is 32
Example of Thread Pool’s Static Configuration¶
[tornado.daemon]
thread_pool_config = {type = "Fixed", size = 20}
In this case, the size of the thread pool is statically fixed at 20. If the provided size is less than 1, then 1 will be used be default.
Structure and Configuration: Retry Strategy Configuration¶
Tornado allows the configuration of a global retry strategy to be applied when the execution of an Action fails.
A retry strategy is composed by:
retry policy: the policy that defines whether an action execution should be retried after an execution failure;
backoff policy: the policy that defines the sleep time between retries.
Valid values for the retry policy are:
{type = "MaxRetries", retries = 5}=> A predefined maximum amount of retry attempts. This is the default value with a retries set to 20.{type = "None"}=> No retries are performed.{type = "Infinite"}=> The operation will be retried an infinite number of times. This setting must be used with extreme caution as it could fill the entire memory buffer preventing Tornado from processing incoming events.
Valid values for the backoff policy are:
{type = "Exponential", ms = 1000, multiplier = 2 }: It increases the back off period for each retry attempt in a given set using the exponential function. The period to sleep on the first backoff is thems; themultiplieris instead used to calculate the next backoff interval from the last. This is the default configuration.{type = "None"}: No sleep time between retries. This is the default value.{type = "Fixed", ms = 1000 }: A fixed amount of milliseconds to sleep between each retry attempt.{type = "Variable", ms = [1000, 5000, 10000]}: The amount of milliseconds between two consecutive retry attempts.The time to wait after ‘i’ retries is specified in the vector at position ‘i’.
If the number of retries is bigger than the vector length, then the last value in the vector is used. For example:
ms = [111,222,333]-> It waits 111 ms after the first failure, 222 ms after the second failure and then 333 ms for all following failures.
Example of a complete Retry Strategy configuration¶
[tornado.daemon]
retry_strategy.retry_policy = {type = "Infinite"}
retry_strategy.backoff_policy = {type = "Variable", ms = [1000, 5000, 10000]}
When not provided explicitly, the following default Retry Strategy is used:
[tornado.daemon]
retry_strategy.retry_policy = {type = "MaxRetries", retries = 20}
retry_strategy.backoff_policy = {type = "Exponential", ms = 1000, multiplier = 2 }
Structure and Configuration: Enable the TCP event socket¶
Enabling the TCP event socket server allows Tornado to receive events through a direct TCP connection.
The TCP event socket configuration entries are available in the
tornado.toml file. Example of the TCP socket section the
tornado.toml file:
# Whether to enable the TCP listener
event_tcp_socket_enabled = true
# The IP address where we will listen for incoming events.
event_socket_ip = "127.0.0.1"
#The port where we will listen for incoming events.
event_socket_port = 4747
In this case, Tornado will listen for incoming events on the TCP address
127.0.0.1:4747.
Structure and Configuration: Enable the Nats connection¶
Enabling the Nats connection allows Tornado to receive events published on a Nats cluster.
The Nats configuration entries are available in the tornado.toml
file. Example of the Nats section the tornado.toml file:
# Whether to connect to the NATS server
nats_enabled = true
# The addresses of the NATS server
nats.client.addresses = ["127.0.0.1:4222"]
# The NATS Subject where tornado will subscribe and listen for incoming events
nats.subject = "tornado.events"
In this case, Tornado will connect to the “test-cluster” and listen for incoming events published on “tornado.events” subject. Also, since nats.client.auth.type is not provided, Tornado will not authenticate to the NATS server.
At the moment, when the nats_enabled entry is set to true, it is
required that the Nats server is available at Tornado startup.
Structure and Configuration: Nats authentication¶
Available authentication types for Tornado are:
None: Tornado does not authenticate to the NATS server
Tls: Tornado authenticates to the NATS server via certificates with TLS
If not differently specified, Tornado will use the None authentication type.
If you want instead to enable TLS authentication to the NATS server you need something similar to the following configuration:
# Whether to connect to the NATS server
nats_enabled = true
# The addresses of the NATS server
nats.client.addresses = ["127.0.0.1:4222"]
# The NATS Subject where tornado will subscribe and listen for incoming events
nats.subject = "tornado.events"
# The type of authentication used when connecting to the NATS server
#nats.client.auth.type = "None"
nats.client.auth.type = "Tls"
# The path to a pkcs12 bundle file which contains the certificate and private key to authenicate to the NATS server
nats.client.auth.path_to_pkcs12_bundle = "/path/to/pkcs12/bundle.pfx"
# The password used to decrypt the pkcs12 bundle
nats.client.auth.pkcs12_bundle_password = "mypwd"
# The path to a root certificate (in .pem format) to trust in addition to system's trust root.
# May be useful if the NATS server is not trusted by the system as default. Optional
#nats.client.auth.path_to_root_certificate = "/path/to/root/certificate.crt.pem"
In this case Tornado will authenticate to the NATS server using the
certificate in the file specified in the field
nats.client.auth.path_to_pkcs12_bundle, using the password mypwd
to decrypt the file.
Structure and Configuration: The Archive Executor¶
The Archive Executor processes and
executes Actions of type “archive”. This Executor configuration is
specified in the archive_executor.toml file in the Tornado config
folder.
For instance, if Tornado is started with the command:
tornado --config-dir=/tornado/config
then the configuration file’s full path will be
/tornado/config/archive_executor.toml.
The archive_executor.toml file has the following structure:
base_path = "./target/tornado-log"
default_path = "/default/file.log"
file_cache_size = 10
file_cache_ttl_secs = 1
[paths]
"one" = "/one/file.log"
More details about the meaning of each entry and how the archive executor functions can be found in the executor documentation.
Structure and Configuration: The Elasticsearch Executor¶
The Elasticsearch Executor
processes and executes Actions of type “elasticsearch”. The
configuration for this Executor is specified in the
elasticsearch_executor.toml file into the Tornado config folder.
For instance, if Tornado is started with the command:
tornado --config-dir=/tornado/config
then the configuration file’s full path will be
/tornado/config/elasticsearch_executor.toml.
The elasticsearch_executor.toml has an optional default_auth
section that allows to define the default authentication method to be
used with Elasticsearch. An action can override the default method by
specifying the auth payload parameter. All the authentication
types defined in Elasticsearch Executor are supported.
In case the default_auth section is omitted, no default
authentication is available.
Defining default Authentication in elasticsearch_executor.toml¶
Connect without authentication:
[default_auth] type = "None"
Authentication with PEM certificates:
[default_auth] type = "PemCertificatePath" certificate_path = "/path/to/tornado/conf/certs/tornado.crt.pem" private_key_path = "/path/to/tornado/conf/certs/private/tornado.key.pem" ca_certificate_path = "/path/to/tornado/conf/certs/root-ca.crt"
More details about the Executor can be found in the Elasticsearch Executor.
Structure and Configuration: The Foreach Executor¶
The foreach Executor allows the recursive executions of a set of actions with dynamic parameters.
More details about the Executor can be found in the foreach executor.
Structure and Configuration: The Icinga 2 Executor¶
The Icinga 2 Executor processes and
executes Actions of type “icinga2”. The configuration for this
executor is specified in the icinga2_client_executor.toml file
into the Tornado config folder.
For instance, if Tornado is started with the command:
tornado --config-dir=/tornado/config
then the configuration file’s full path will be
/tornado/config/icinga2_client_executor.toml.
The icinga2_client_executor.toml has the following configuration options:
server_api_url: The complete URL of the Icinga 2 APIs.
username: The username used to connect to the Icinga 2 APIs.
password: The password used to connect to the Icinga 2 APIs.
disable_ssl_verification: If true, the client will not verify the SSL certificate of the Icinga 2 server.
(optional) timeout_secs: The timeout in seconds for a call to the Icinga 2 APIs. If not provided, it defaults to 10 seconds.
More details about the Executor can be found in the Icinga 2 Executor documentation.
Structure and Configuration: The Director Executor¶
The Director Executor processes
and executes Actions of type “director”. The configuration for this
executor is specified in the director_client_executor.toml file into
the Tornado config folder.
For instance, if Tornado is started with the command:
tornado --config-dir=/tornado/config
then the configuration file’s full path will be
/tornado/config/director_client_executor.toml.
The director_client_executor.toml has the following configuration options:
server_api_url: The complete URL of the Director APIs.
username: The username used to connect to the Director APIs.
password: The password used to connect to the Director APIs.
disable_ssl_verification: If true, the client will not verify the SSL certificate of the Director REST API server.
(optional) timeout_secs: The timeout in seconds for a call to the Icinga Director REST APIs. If not provided, it defaults to 10 seconds.
More details about the Executor can be found in the Director executor documentation.
Structure and Configuration: The Logger Executor¶
The Logger Executor logs the whole Action body to the standard log at the info level.
This Executor has no specific configuration.
Structure and Configuration: The Script Executor¶
The Script Executor processes and executes Actions of type “script”.
This Executor has no specific configuration, since everything required for script execution is contained in the Action itself as described in the Executor documentation.
Structure and Configuration: The Smart Monitoring Check Result Executor¶
The configuration of the smart_monitoring_check_result Executor is specified in the
smart_monitoring_check_result.toml file into the Tornado config
folder.
The smart_monitoring_check_result.toml has the following configuration options:
pending_object_set_status_retries_attempts: The number of attempts to perform a
process_check_resultfor an object in pending state.pending_object_set_status_retries_sleep_ms: The sleep time in ms between attempts to perform a process_check_result for an object in pending state.
The smart_monitoring_check_result.toml file is optional; if not
provided, the following default values will be used:
pending_object_set_status_retries_attempts = 2
pending_object_set_status_retries_sleep_ms = 1000
More details about the Executor can be found in the smart_monitoring_check_result documentation.
Processing Tree Configuration¶
The location of configuration files in the file system is pre-configured in NetEye. NetEye automatically starts Tornado as follows:
Reads the configuration from the
/neteye/shared/tornado/confdirectoryStarts the Tornado Engine
Searches for Filter and Rule definitions in
/neteye/shared/tornado/conf/rules.d
The structure of this last directory reflects the Processing Tree structure. Each subdirectory can contain either:
A Filter and a set of sub directories corresponding to the Filter’s children
A Ruleset
Each individual Rule or Filter to be included in the processing tree must be saved in its own, JSON formatted file.
Hint
Tornado will ignore all other file types.
For instance, consider this directory structure:
/tornado/config/rules
|- node_0
| |- 0001_rule_one.json
| \- 0010_rule_two.json
|- node_1
| |- inner_node
| | \- 0001_rule_one.json
| \- filter_two.json
\- filter_one.json
In this example, the processing tree is organized as follows:
The root node is a filter named filter_one.
The filter filter_one has two child nodes: node_0 and node_1:
node_0 is a Ruleset that contains two rules called rule_one and rule_two, with an implicit filter that forwards all incoming events to both of its child rules.
node_1 is a filter with a single child named inner_node. Its filter filter_two determines which incoming events are passed to its child node.
inner_node is a Ruleset with a single rule called rule_one.
Within a Ruleset, the lexicographic order of the file names
determines the execution order. The rule filename is composed of two
parts separated by the first _ (underscore) symbol. The first part
determines the rule execution order, and the second is the rule name.
For example:
0001_rule_one.json -> 0001 determines the execution order, “rule_one” is the rule name
0010_rule_two.json -> 0010 determines the execution order, “rule_two” is the rule name
Note
A Rule name must be unique within its own Ruleset, but two rules with the same name may exist in different Rulesets.
Similar to what happens for Rules, Filter names are also derived from the filenames. However, in this case, the entire filename corresponds to the Filter name.
In the example above, the “filter_one” node is the entry point of the processing tree. When an Event arrives, the Matcher will evaluate whether it matches the filter condition, and will pass the Event to one (or more) of the filter’s children. Otherwise it will ignore it.
A node’s children are processed independently. Thus node_0 and node_1 will be processed in isolation and each of them will be unaware of the existence and outcome of the other. This process logic is applied recursively to every node.
Structure of a Filter¶
A Filter contains these properties:
filter name: A string value representing a unique Filter identifier. It can be composed only of letters, numbers and the “_” (underscore) character; it corresponds to the filename, stripped from its .json extension.description: A string providing a high-level description of the filter.active: A boolean value; iffalse, the Filter’s children will be ignored.filter: A boolean operator that, when applied to an event, returnstrueorfalse. This operator determines whether an Event matches the Filter; consequently, it determines whether an Event will be processed by the Filter’s inner nodes.
Implicit Filters
If a Filter is omitted, Tornado will automatically infer an implicit filter that passes through all Events. This feature allows for less boiler-plate code when a Filter is only required to blindly forward all Events to the internal rule sets.
For example, if filter_one.json is a Filter that allows all Events to pass through, then this processing tree:
root
|- node_0
| |- ...
|- node_1
| |- ...
\- filter_one.json
is equivalent to:
root
|- node_0
| |- ...
\- node_1
|- ...
Note that in the second tree we removed the filter_one.json file. In this case, Tornado will automatically generate an implicit Filter for the root node, and all incoming Events will be dispatched to each child node.
Filters available by default
The Tornado Processing Tree provides some out of the box Filters, which match all, and only, the Events originated by some given tenant. For more information on tenants in NetEye visit the dedicated page.
These Filters are created at the top level of the Processing Tree, in such a way that it is possible to set up tenant-specific Tornado pipelines.
Given for example a tenant named acme, the matching condition of the
Filter for the acme tenant will be defined as:
{
"type": "equals",
"first": "${event.metadata.tenant_id}",
"second": "acme"
}
Keep in mind that these Filters must never be deleted nor modified, because they will be automatically re-created.
Note
NetEye generates one Filter for each tenant, including the default master
tenant.
Structure of a Rule¶
A Rule is composed of a set of properties, constraints and actions.
Basic Properties
rule name: A string value representing a unique rule identifier. It can be composed only of alphabetical characters, numbers and the “_” (underscore) character.description: A string value providing a high-level description of the rule.continue: A boolean value indicating whether to proceed with the event matching process if the current rule matches.active: A boolean value; iffalse, the rule is ignored.
When the configuration is read from the file system, the rule name is automatically inferred from the filename by removing the extension and everything that precedes the first ‘_’ (underscore) symbol. For example:
0001_rule_one.json -> 0001 determines the execution order, “rule_one” is the rule name
0010_rule_two.json -> 0010 determines the execution order, “rule_two” is the rule name
Constraints
The constraint section contains the tests that determine whether or not an event matches the rule. There are two types of constraints:
WHERE: A set of operators that when applied to an event returns
trueorfalseWITH: A set of regular expressions that extract values from an Event and associate them with named variables
An event matches a rule if and only if the WHERE clause evaluates to
true and all regular expressions in the WITH clause return non-empty
values.
The following operators are available in the WHERE clause. Check also the examples in the dedicated section to see how to use them, including example rules.
‘contains’: Evaluates whether the first argument contains the second one. It can be applied to strings, arrays, and maps. The operator can also be called with the alias ‘contain’.
‘containsIgnoreCase’: Evaluates whether the first argument contains, in a case-insensitive way, the string passed as second argument. This operator can also be called with the alias ‘containIgnoreCase’.
‘equals’: Compares any two values (including, but not limited to, arrays, maps) and returns whether or not they are equal. An alias for this operator is ‘equal’.
‘equalsIgnoreCase’: Compares two strings and returns whether or not they are equal in a case-insensitive way. The operator can also be called with the alias ‘equalIgnoreCase’.
‘ge’: Compares two values and returns whether the first value is greater than or equal to the second one. If one or both of the values do not exist, it returns
false.‘gt’: Compares two values and returns whether the first value is greater than the second one. If one or both of the values do not exist, it returns
false.‘le’: Compares two values and returns whether the first value is less than or equal to the second one. If one or both of the values do not exist, it returns
false.‘lt’: Compares two values and returns whether the first value is less than the second one. If one or both of the values do not exist, it returns
false.‘ne’: This is the negation of the ‘equals’ operator. Compares two values and returns whether or not they are different. It can also be called with the aliases ‘notEquals’ and ‘notEqual’.
‘regex’: Evaluates whether a field of an event matches a given regular expression.
‘AND’: Receives an array of operator clauses and returns
trueif and only if all of them evaluate totrue.‘OR’: Receives an array of operator clauses and returns
trueif at least one of the operators evaluates totrue.‘NOT’: Receives one operator clause and returns
trueif the operator clause evaluates tofalse, while it returnsfalseif the operator clause evaluates totrue.
We use the Rust Regex library (see its github project home page ) to evaluate regular expressions provided by the WITH clause and by the regex operator. You can also refer to its dedicated documentation for details about its features and limitations.
Actions
An Action is an operation triggered when an Event matches a Rule.
Reading Event Fields
A Rule can access Event fields through the “${” and “}” delimiters. To do so, the following conventions are defined:
The ‘.’ (dot) char is used to access inner fields.
Keys containing dots are escaped with leading and trailing double quotes.
Double quote chars are not accepted inside a key.
For example, given the incoming event:
{
"type": "trap",
"created_ms": 1554130814854,
"payload":{
"protocol": "UDP",
"oids": {
"key.with.dots": "38:10:38:30.98"
}
}
}
The rule can access the event’s fields as follows:
${event.type}: Returns trap${event.payload.protocol}: Returns UDP${event.payload.oids."key.with.dots"}: Returns 38:10:38:30.98${event.payload}: Returns the entire payload${event}: Returns the entire event${event.metadata.key}: Returns the value of the key key from the metadata. The metadata is a special field of an event created by Tornado to store additional information where needed (e.g. the tenant_id, etc.)
String interpolation
An action payload can also contain text with placeholders that Tornado will replace at runtime. The values to be used for the substitution are extracted from the incoming Events following the conventions mentioned in the previous section; for example, using that Event definition, this string in the action payload:
Received a ${event.type} with protocol ${event.payload.protocol}
produces:
*Received a trap with protocol UDP*
Note
Only values of type String, Number, Boolean and null are valid. Consequently, the interpolation will fail, and the action will not be executed, if the value associated with the placeholder extracted from the Event is an Array, a Map, or undefined.
Example of Filters¶
Using a Filter to Create Independent Pipelines
We can use Filters to organize coherent set of Rules into isolated pipelines.
In this example we will see how to create two independent pipelines, one that receives only events with type ‘email’, and the other that receives only those with type ‘trapd’.
Our configuration directory will look like this::
rules.d
|- email
| |- ruleset
| | |- ... (all rules about emails here)
| \- only_email_filter.json
|- trapd
| |- ruleset
| | |- ... (all rules about trapds here)
| \- only_trapd_filter.json
\- filter_all.json
This processing tree has a root Filter filter_all that matches all events. We have also defined two inner Filters; the first, only_email_filter, only matches events of type ‘email’. The other, only_trapd_filter, matches just events of type ‘trap’.
Therefore, with this configuration, the rules defined in email/ruleset receive only email events, while those in trapd/ruleset receive only trapd events.
This configuration can be further simplified by removing the filter_all.json file:
rules.d
|- email
| |- ruleset
| | |- ... (all rules about emails here)
| \- only_email_filter.json
\- trapd
|- ruleset
| |- ... (all rules about trapds here)
\- only_trapd_filter.json
In this case, in fact, Tornado will generate an implicit Filter for the root node and the runtime behavior will not change.
Below is the content of our JSON Filter files.
Content of filter_all.json (if provided):
{
"description": "This filter allows every event",
"active": true
}
Content of only_email_filter.json:
{
"description": "This filter allows events of type 'email'",
"active": true,
"filter": {
"type": "equals",
"first": "${event.type}",
"second": "email"
}
}
Content of only_trapd_filter.json:
{
"description": "This filter allows events of type 'trapd'",
"active": true,
"filter": {
"type": "equals",
"first": "${event.type}",
"second": "trapd"
}
}
Multi Tenancy Roles Configuration¶
If your NetEye installation is tenant aware, roles associated to each user must be configured to limit their access only the processing trees they are allowed to.
In the NetEye roles (), add or edit the role
related to the tenant limited users. In the detail of the role configuration you can
find the tornadocarbon module section. You can set the tenant ID in the
tornadocarbon/tenant_id restriction.
Hint
You can find the list of available Tenant IDs by reading the directory
names in /etc/neteye-satellites.d/. You can use this command:
neteye# basename -a $(ls -d /etc/neteye-satellite.d/*/)
Tornado Executors¶
Director Executor¶
The Director Executor is an application that extracts data from a Tornado Action and prepares it to be sent to the Icinga Director REST API; it expects a Tornado Action to include the following elements in its payload:
An action_name: The Director action to perform.
An action_payload (optional): The payload of the Director action.
An icinga2_live_creation (optional): Boolean value, which determines whether to create the specified Icinga Object also in Icinga 2.
Valid values for action_name are:
create_host: creates an object of type
hostin the Directorcreate_service: creates an object of type
servicein the Director
The action_payload should contain at least all mandatory parameters expected by the Icinga Director REST API for the type of object you want to create.
An example of a valid Tornado Action is:
{
"id": "director",
"payload": {
"action_name": "create_host",
"action_payload": {
"object_type": "object",
"object_name": "my_host_name",
"address": "127.0.0.1",
"check_command": "hostalive",
"vars": {
"location": "Bolzano"
}
},
"icinga2_live_creation": true
}
}
Logger Executor¶
An Executor that logs received Actions: it simply outputs the whole Action body to the standard log at the info level.
Script Executor¶
An Executor that runs custom shell scripts on a Unix-like system. To be correctly processed by this Executor, an Action should provide two entries in its payload: the path to a script on the local filesystem of the Executor process, and all the arguments to be passed to the script itself.
The script path is identified by the payload key script. It is important to verify that the Executor has both read and execute rights at that path.
The script arguments are identified by the payload key args; if present, they are passed as command line arguments when the script is executed.
An example of a valid Action is:
{
"id": "script",
"payload" : {
"script": "./usr/share/scripts/my_script.sh",
"args": [
"tornado",
"rust"
]
}
}
In this case the Executor will launch the script my_script.sh with the arguments “tornado” and “rust”. Consequently, the resulting command will be:
neteye# ./usr/share/scripts/my_script.sh tornado rust
Other Ways of Passing Arguments
There are different ways to pass the arguments for a script:
Passing arguments as a String:
{ "id": "script", "payload" : { "script": "./usr/share/scripts/my_script.sh", "args": "arg_one arg_two -a --something else" } }
If args is a String, the entire String is appended as a single argument to the script. In this case the resulting command will be:
neteye# ./usr/share/scripts/my_script.sh "arg_one arg_two -a --something else"
Passing arguments in an array:
{ "id": "script", "payload" : { "script": "./usr/share/scripts/my_script.sh", "args": [ "--arg_one tornado", "arg_two", true, 100 ] } }
Here the argument’s array elements are passed as four arguments to the script in the exact order they are declared. In this case the resulting command will be:
neteye# ./usr/share/scripts/my_script.sh "--arg_one tornado" arg_two true 100
Passing arguments in a map:
{ "id": "script", "payload" : { "script": "./usr/share/scripts/my_script.sh", "args": { "arg_one": "tornado", "arg_two": "rust" } } }
When arguments are passed in a map, each entry in the map is considered to be a (option key, option value) pair. Each pair is passed to the script using the default style to pass options to a Unix executable which is –key followed by the value. Consequently, the resulting command will be:
neteye# ./usr/share/scripts/my_script.sh --arg_one tornado --arg_two rust
Please note that ordering is not guaranteed to be preserved in this case, so the resulting command line could also be:
neteye# ./usr/share/scripts/my_script.sh --arg_two rust --arg_one tornado
Thus if the order of the arguments matters, you should pass them using either the string- or the array-based approach.
Passing no arguments:
{ "id": "script", "payload" : { "script": "./usr/share/scripts/my_script.sh" } }
Since arguments are not mandatory, they can be omitted. In this case the resulting command will simply be:
neteye# ./usr/share/scripts/my_script.sh
Monitoring Executor¶
Warning
The monitoring Executor is deprecated, please use the Smart Monitoring Check Result Executor, which is equivalent but it is easier to configure.
The Monitoring Executor permits to perform Icinga
process-check-results also in the case that the Icinga object for
which you want to perform the process-check-result does not yet
exist.
This is done by means of executing the action process-check-result
with the Icinga Executor, and by executing the actions create_host
or create_service with the Director Executor, in case the
underlying Icinga objects do not yet exist in Icinga.
Warning
The Monitoring Executor requires the live-creation feature of the Icinga Director to be exposed in the REST API. If this is not the case, the actions of this Executor will always fail in case the Icinga Objects are not already present in Icinga 2.
This Executor expects a Tornado Action to include the following elements in its payload:
An action_name: The Monitoring action to perform.
A process_check_result_payload: The payload for the Icinga 2
process-check-resultaction.A host_creation_payload: The payload which will be sent to the Icinga Director REST API for the host creation.
A service_creation_payload: The payload which will be sent to the Icinga Director REST API for the service creation (mandatory only in case action_name is
create_and_or_process_service_passive_check_result).
Valid values for action_name are:
create_and_or_process_host_passive_check_result: sets the
passive check resultfor ahost, and, if necessary, it also creates the host.create_and_or_process_service_passive_check_result: sets the
passive check resultfor aservice, and, if necessary, it also creates the service.
The process_check_result_payload should contain at least all
mandatory parameters expected by the Icinga API to perform the action.
The object on which you want to set the passive check result must be
specified with the field host in case of action
create_and_or_process_host_passive_check_result, and service in
case of action create_and_or_process_service_passive_check_result
(e.g. specifying a set of objects on which to apply the
passive check result with the parameter filter is not valid)
The host_creation_payload should contain at least all mandatory parameters expected by the Icinga Director REST API to perform the creation of a host.
The servie_creation_payload should contain at least all mandatory parameters expected by the Icinga Director REST API to perform the creation of a service.
An example of a valid Tornado Action is:
{
"id": "monitoring",
"payload": {
"action_name": "create_and_or_process_service_passive_check_result",
"process_check_result_payload": {
"exit_status": "2",
"plugin_output": "Output message",
"service": "myhost!myservice",
"type": "Service"
},
"host_creation_payload": {
"object_type": "Object",
"object_name": "myhost",
"address": "127.0.0.1",
"check_command": "hostalive",
"vars": {
"location": "Rome"
}
},
"service_creation_payload": {
"object_type": "Object",
"host": "myhost",
"object_name": "myservice",
"check_command": "ping"
}
}
}
The flowchart shown in Fig. 159 helps to understand the behaviour of the Monitoring Executor in relation to Icinga 2 and Icinga Director REST APIs.
Fig. 159 Flowchart of Monitoring Executor.¶
Foreach Executor¶
An Executor that loops through a set of data and executes a list of actions for each entry; it extracts all values from an array of elements and injects each value to a list of action under the item key.
There are two mandatory configuration entries in its payload:
target: the array of elements
actions: the array of action to execute
For example, given this rule definition:
{
"name": "do_something_foreach_value",
"description": "This uses a foreach loop",
"continue": true,
"active": true,
"constraint": {
"WITH": {}
},
"actions": [
{
"id": "foreach",
"payload": {
"target": "${event.payload.values}",
"actions": [
{
"id": "logger",
"payload": {
"source": "${event.payload.source}",
"value": "the value is ${item}"
}
},
{
"id": "archive",
"payload": {
"event": "${event}",
"item_value": "${item}"
}
}
]
}
}
]
}
When an event with this payload is received:
{
"type": "some_event",
"created_ms": 123456,
"payload":{
"values": ["ONE", "TWO", "THREE"],
"source": "host_01"
}
}
Then the target of the foreach action is the array
["ONE", "TWO", "THREE"]; consequently, each one of the two inner
actions is executed three times; the first time with item = “ONE”,
then with item = “TWO” and, finally, with item = “THREE”.
Archive Executor¶
The Archive Executor writes the Events from the received Actions to a file.
Requirements and Limitations
The archive Executor can only write to locally mounted file systems. In addition, it needs read and write permissions on the folders and files specified in its configuration.
Configuration
The archive Executor has the following configuration options:
file_cache_size: The number of file descriptors to be cached. You can improve overall performance by keeping files from being continuously opened and closed at each write.
file_cache_ttl_secs: The Time To Live of a file descriptor. When this time reaches 0, the descriptor will be removed from the cache.
base_path: A directory on the file system where all logs are written. Based on their type, rule Actions received from the Matcher can be logged in subdirectories of the base_path. However, the archive Executor will only allow files to be written inside this folder.
default_path: A default path where all Actions that do not specify an
archive_typein the payload are loggedpaths: A set of mappings from an archive_type to an
archive_path, which is a subpath relative to the base_path. The archive_path can contain variables, specified by the syntax${parameter_name}, which are replaced at runtime by the values in the Action’s payload.
The archive path serves to decouple the type from the actual subpath, allowing you to write Action rules without worrying about having to modify them if you later change the directory structure or destination paths.
As an example of how an archive_path is computed, suppose we have the following configuration:
base_path = "/tmp"
default_path = "/default/out.log"
file_cache_size = 10
file_cache_ttl_secs = 1
[paths]
"type_one" = "/dir_one/file.log"
"type_two" = "/dir_two/${hostname}/file.log"
and these three incoming actions:
action_one:
{ "id": "archive", "payload": { "archive_type": "type_one", "event": "__the_incoming_event__" } }
action_two:
{ "id": "archive", "payload": { "archive_type": "type_two", "hostname": "net-test", "event": "__the_incoming_event__" } }
action_three:
{ "id": "archive", "payload": { "event": "__the_incoming_event__" } }
then:
action_one will be archived in /tmp/dir_one/file.log
action_two will be archived in /tmp/dir_two/net-test/file.log
action_three will be archived in /tmp/default/out.log
The archive Executor expects an Action to include the following elements in the payload:
An event: The Event to be archived should be included in the payload under the key
eventAn archive type (optional): The archive type is specified in the payload under the key
archive_type
When an archive_type is not specified, the default_path is used (as in
action_three). Otherwise, the Executor will use the archive_path in the
paths configuration corresponding to the archive_type key
(action_one and action_two).
When an archive_type is specified but there is no corresponding key in
the mappings under the paths configuration, or it is not possible to
resolve all path parameters, then the Event will not be archived.
Instead, the archiver will return an error.
The Event from the payload is written into the log file in JSON format, one event per line.
Elasticsearch Executor¶
The Elasticsearch Executor is a functionality that extracts data from a Tornado Action and sends it to Elasticsearch.
The Executor expects a Tornado Action that includes the following elements in its payload:
An endpoint : The Elasticsearch endpoint which Tornado will call to create the Elasticsearch document
An index : The name of the Elasticsearch index in which the document will be created
An data: The content of the document that will be sent to Elasticsearch
(optional) An auth: a method of authentication, see below
An example of a valid Tornado Action is a json document like this:
{
"id": "elasticsearch",
"payload": {
"endpoint": "http://localhost:9200",
"index": "tornado-example",
"data": {
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
}
}
The Elasticsearch Executor will create a new document in the specified Elasticsearch index for each action executed; also the specified index will be created if it does not already exist.
In the above json document, no authentication is specified, therefore
the default authentication method created during the Executor creation
is used. This method is saved in a tornado configuration file
(elasticsearch_executor.toml) and can be overridden for each Tornado
Action, as described in the next section.
Elasticsearch authentication
When the Elasticsearch Executor is created, a default authentication method can be specified and will be used to authenticate to Elasticsearch, if not differently specified by the action. On the contrary, if a default method is not defined at creation time, then each action that does not specify an authentication method will fail.
To use a specific authentication method the action should include the
auth field with either of the following authentication types:
None or PemCertificatePath, like shown in the following
examples.
None: the client connects to Elasticsearch without authentication
Example:
{ "id": "elasticsearch", "payload": { "index": "tornado-example", "endpoint": "http://localhost:9200", "data": { "user": "myuser" }, "auth": { "type": "None" } } }
PemCertificatePath: the client connects to Elasticsearch using the PEM certificates read from the local file system. When this method is used, the following information must be provided:
certificate_path: path to the public certificate accepted by Elasticsearch
private_key_path: path to the corresponding private key
ca_certificate_path: path to CA certificate needed to verify the identity of the Elasticsearch server
Example:
{ "id": "elasticsearch", "payload": { "index": "tornado-example", "endpoint": "http://localhost:9200", "data": { "user": "myuser" }, "auth": { "type": "PemCertificatePath", "certificate_path": "/path/to/tornado/conf/certs/tornado.crt.pem", "private_key_path": "/path/to/tornado/conf/certs/private/tornado.key.pem", "ca_certificate_path": "/path/to/tornado/conf/certs/root-ca.crt" } } }
Icinga 2 Executor¶
The Icinga 2 Executor extracts data from a Tornado Action and prepares it to be sent to the Icinga 2 API.
In more details, this Executor expects a Tornado Action to include the following elements in its payload:
An icinga2_action_name: The Icinga 2 action to perform
An icinga2_action_payload (optional): The parameters of the Icinga 2 action
The icinga2_action_name should match one of the existing Icinga 2 actions.
The icinga2_action_payload should contain at least all mandatory parameters expected by the specific Icinga 2 action.
An example of a valid Tornado Action is:
{
"id": "icinga2",
"payload": {
"icinga2_action_name": "process-check-result",
"icinga2_action_payload": {
"exit_status": "${event.payload.exit_status}",
"plugin_output": "${event.payload.plugin_output}",
"filter": "host.name==\"example.localdomain\"",
"type": "Host"
}
}
}
Smart Monitoring Check Result Executor¶
The Smart Monitoring Check Result Executor allows to perform an Icinga
process-check-results in case the Icinga 2 object for which you
want to carry out that action does not exist. Moreover, this Executor also ensures
that no outdated process-check-result will overwrite newer check results
already present in Icinga 2.
In case the underlying Icinga 2 objects do not exist in Icinga 2,
the actions create_host or create_service are
performed via the Director Executor.
Warning
The Smart Monitoring Check Result Executor requires the live-creation feature of the Icinga Director to be exposed in the REST API. If this is not the case, the actions of this Executor will always fail in case the Icinga Objects are not already present in Icinga 2.
Note however, that the Icinga agent cannot be created live using Smart Monitoring Executor because it always requires a defined endpoint in the configuration which is not possible since the Icinga API doesn’t support live-creation of an endpoint.
To ensure that outdated check results are not processed, the action
process-check-result is carried out by the
Icinga 2 Executor with the parameters execution_start
and execution_end inherited by the Action definition or set equal
to the value of the created_ms property of the originating Tornado
Event. Section
Discarded Check Results
explains how the Executor handles these cases.
The Tornado Action sent to this Executor shall include the following elements in its payload:
A check_result: The basic data to build the Icinga 2
process-check-resultaction payloadA host: The data to build the payload which will be sent to the Icinga Director REST API for the host creation
A service: The data to build the payload which will be sent to the Icinga Director REST API for the service creation (optional)
The check_result should contain all mandatory parameters expected by the Icinga API except the following ones that are automatically filled by the Executor:
hostservicetype
The host and service should contain all mandatory parameters
expected by the Icinga Director REST API to perform the creation of a
host and/or a service, except object_type.
The service key is optional. When it is included in the action
payload, the Executor will invoke the process-check-results call to
set the status of a service; otherwise, it will set the one of a host.
An example of a valid Tornado Action is to set the status of the service
myhost|myservice:
{
"id": "smart_monitoring_check_result",
"payload": {
"check_result": {
"exit_status": "2",
"plugin_output": "Output message"
},
"host": {
"object_name": "myhost",
"address": "127.0.0.1",
"check_command": "hostalive",
"vars": {
"location": "Rome"
}
},
"service": {
"object_name": "myservice",
"check_command": "ping"
}
}
}
By simply removing the service key, the same action will set the
status of the host myhost:
{
"id": "smart_monitoring_check_result",
"payload": {
"check_result": {
"exit_status": "2",
"plugin_output": "Output message"
},
"host": {
"object_name": "myhost",
"address": "127.0.0.1",
"check_command": "hostalive",
"vars": {
"location": "Rome"
}
}
}
}
The flowchart shown in Fig. 159 helps to understand the behaviour of the Monitoring Executor in relation to Icinga 2 and Icinga Director REST APIs.
Retry logic
When a new object is created, after the call to the
process_check_result the Executor calls the Icinga /v1/objects
API to check whether the new object is still in PENDING state. In
case the object is found to be pending, the Executor will call again the
process_check_result API, for a predefined number of attempts, until
the check to the object state returns that it is not PENDING
anymore.
Discarded Check Results
Some process-check-results may be discarded by Icinga 2 if more recent
check results already exist for the target object.
In this situation the Executor does not retry the Action, but
simply logs an error containing the tag DISCARDED_PROCESS_CHECK_RESULT
in the configured Tornado Logger.
The log message showing a discarded process-check-result will be similar
to the following excerpt, enclosed in an ActionExecutionError:
SmartMonitoringExecutor - Process check result action failed with error ActionExecutionError {
message: "Icinga2Executor - Icinga2 API returned an unrecoverable error. Response status: 500 Internal Server Error.
Response body: {\"results\":[{\"code\":409.0,\"status\":\"Newer check result already present. Check result for 'my-host!my-service' was discarded.\"}]}",
can_retry: false,
code: None,
data: {
"payload":{"execution_end":1651054222.0,"execution_start":1651054222.0,"exit_status":0,"plugin_output":"Some process check result","service":"my-host!my-service","type":"Service"},
"tags":["DISCARDED_PROCESS_CHECK_RESULT"],
"url":"https://icinga2-master.neteyelocal:5665/v1/actions/process-check-result",
"method":"POST"
}
}.
Common Logger¶
The tornado_common_logger crate contains the logger configuration for the Tornado components.
The configuration is based on three entries:
level: A list of comma separated logger verbosity levels. Valid values for a level are: trace, debug, info, warn, and error. If only one level is provided, this is used as global logger level. Otherwise, a list of per package levels can be used. E.g.:
level=info: the global logger level is set to infolevel=warn,tornado=debug: the global logger level is set to warn, the tornado package logger level is set to debug
stdout-output: A boolean value that determines whether the Logger should print to standard output. Valid values are true and false.
file-output-path: An optional string that defines a file path in the file system. If provided, the Logger will append any output to that file.
The configuration subsection logger.tracing_elastic_apm allows to configure the connection to Elastic APM for the tracing functionality. The following entries can be configured:
apm_output: Whether the Logger data should be sent to the Elastic APM Server. Valid values are true and false.
apm_server_url: The URL of the Elastic APM Server.
apm_server_api_credentials.id: (Optional) the ID of the API Key for authenticating to the Elastic APM server.
apm_server_api_credentials.key: (Optional) the key of the API Key for authenticating to the Elastic APM server. If apm_server_api_credentials.id and apm_server_api_credentials.key are not provided, they will be read from the file <config_dir>/apm_server_api_credentials.json
exporter.max_queue_size: (Optional) The maximum queue size of the tracing batch exporter to buffer spans for delayed processing. Defaults to
65536.exporter.scheduled_delay_ms: The delay interval in milliseconds between two consecutive exports of batches. Defaults to
5000(5 seconds).exporter.max_export_batch_size: The maximum number of spans to export in a single batch. Defaults to
512.exporter.max_export_timeout_ms: The time (in milliseconds) for which the export can run before it is cancelled. Defaults to
30000(30 seconds).
In Tornado executables, the Logger configuration is usually defined with command line parameters managed by structopt. In that case, the default level is set to warn, stdout-output is disabled and the file-output-path is empty.
For example:
./tornado --level=info --stdout-output --file-output-path=/tornado/log
This website uses cookies that store your theme preferences. These cookies do not store any personally identifiable data.