Configuration¶
El Proxy Configuration¶
The El Proxy is carried out thanks to CLI commands that allow you to use the functionality provided. Running the executable without any arguments returns a list of all available commands and global options that apply to every command.
Available commands:
acknowledge : Acknowledges a corruption in a blockchain.
export-logs : Exports the signed logs from ElasticSearch to a local file.
serve : Starts the El Proxy server ready for processing incoming requests.
verify : Verify the validity of a blockchain.
verify-cpu-bench : Benchmark the underlying hardware for verification.
The El Proxy configuration is partly based on configuration files and partly based on command line parameters. The location of configuration files in the file system is determined at startup based on the provided CLI options. In addition, each command can have specific CLI arguments required.
Global command line parameters:
config-dir: (Optional) The filesystem folder from which the configuration is read. The default path is
/neteye/shared/elastic-blockchain-proxy/conf/.static-config-dir: (Optional) The filesystem folder from which the static configuration (i.e. configuration files that the final user cannot modify) is read. The default path is
/usr/share/elastic-blockchain-proxy.
Available command line parameters for the acknowledge command only:
key-file: The path to the file that contains the iteration 0 signature key
corruption-id: The CorruptionId produced by the verify command to be acknowledged
description: (Optional) A description of the blockchain corruption. It will be prompted if not provided
reason: (Optional) The reason why the corruption happened. It will be prompted if not provided
elasticsearch-authentication-method: (Optional) The method used to authenticate to Elasticsearch. This can be:
none: (Default) the command does not authenticate to Elasticsearch
basicauth: Username and password are used to authenticate. If this method is specified, the following parameter is required (and a password will be prompted during the execution):
elasticsearch-username: the name Elasticsearch user used to perform authentication
pemcertificatepath: PKI user authentication is used. If this method is specified, the following parameters are required:
elasticsearch-client-cert path to the client certificate. A client certificate suitable for the acknowledge command is present under
/neteye/shared/elastic-blockchain-proxy/conf/certs/ElasticBlockchainProxyAcknowledge.crt.pemelasticsearch-client-private-key path to the private key of the client certificate. A client private key suitable for the acknowledge command is present under
/neteye/shared/elastic-blockchain-proxy/conf/certs/private/ElasticBlockchainProxyAcknowledge.key.pemelasticsearch-ca-cert path to the CA certificate to be trusted during the requests to Elasticsearch
For example, if you want to acknowledge the corruption with corruption-id abc123, you can execute the following command:
elastic_blockchain_proxy acknowledge --key-file /path/to/secret/key --corruption-id 'abc123' --elasticsearch-authentication-method 'pemcertificatepath' --elasticsearch-client-cert '/neteye/shared/elastic-blockchain-proxy/conf/certs/ElasticBlockchainProxyAcknowledge.crt.pem' --elasticsearch-client-private-key '/neteye/shared/elastic-blockchain-proxy/conf/certs/private/ElasticBlockchainProxyAcknowledge.key.pem'
Available command line parameters for the export-logs command only:
output-file: The output file path where the exported logs are written
index-name: The name of the target Elasticsearch index to be used
format: (Optional) The output file format. This can be:
ndjson: (Default) the logs are exported in Newline delimited JSON format
from-date: (Optional) An inclusive ‘From’ date limit in ISO 8601 format
to-date: (Optional) An exclusive ‘To’ date limit in ISO 8601 format
batch-size: (Optional) The size of a each read/write operation. Default is 500.
elasticsearch-authentication-method: (Optional) The method used to authenticate to Elasticsearch. This can be:
none: (Default) the command does not authenticate to Elasticsearch
- basicauth: Username and password are used to authenticate. If this method is specified,
the following parameter is required (and a password will be prompted during the execution):
elasticsearch-username: the name Elasticsearch user used to perform authentication
pemcertificatepath: PKI user authentication is used. If this method is specified, the following parameters are required:
elasticsearch-client-cert path to the client certificate
elasticsearch-client-private-key path to the private key of the client certificate
elasticsearch-ca-cert path to the CA certificate to be trusted during the requests to Elasticsearch
Available command line parameters for the verify command only:
index-name: The name of the target Elasticsearch index to be used
key-file: The path to the file that contains the iteration 0 signature key
batch-size: (Optional) The size of each read/verify operation. Default is 500.
concurrent-batches: (Optional) The number of concurrent threads verifying the blockchain. Default is 2.
from-iteration: (Optional) The inclusive iteration number from which the verification has to be performed. Default is 0.
elasticsearch-authentication-method: (Optional) The method used to authenticate to Elasticsearch. This can be:
none: (Default) the command does not authenticate to Elasticsearch
basicauth: Username and password are used to authenticate. If this method is specified, the following parameter is required (and a password will be prompted during the execution):
elasticsearch-username: the name Elasticsearch user used to perform authentication
pemcertificatepath: PKI user authentication is used. If this method is specified, the following parameters are required:
elasticsearch-client-cert path to the client certificate
elasticsearch-client-private-key path to the private key of the client certificate
elasticsearch-ca-cert path to the CA certificate to be trusted during the requests to Elasticsearch
For example, given a blockchain which refers to:
module:
elproxysignedcustomer:
mycustomerretention:
6_monthsblockchain_tag:
0
You can verify the blockchain with the command:
elastic_blockchain_proxy verify --index-name '*-*-elproxysigned-mycustomer-6_months-0-*' --key-file /path/to/secret/key --elasticsearch-authentication-method 'pemcertificatepath' --elasticsearch-client-cert '/neteye/local/elasticsearch/conf/certs/admin.crt.pem' --elasticsearch-client-private-key '/neteye/local/elasticsearch/conf/certs/private/admin.key.pem'
Warning
To verify blockchains built before the upgrade to NetEye 4.18 (blockchains which do not include the fields retention and blockchain_tag in the name of the indices), please use instead an index-name a like the following:
elastic_blockchain_proxy verify --index-name '*-*-elproxysigned-mycustomer-*,-*-*-elproxysigned-mycustomer-*-*-*' --key-file /path/to/secret/key
Available command line parameters for the verify-cpu-bench command only:
batch-size: (Optional) The size of each read/verify operation. Default is 1000.
n-logs: (Optional) The number of logs to verify. Default is 1,000,000.
log-size: (Optional) The size of each log in KB. Default is 1KB.
concurrent-batches: (Optional) The number of concurrent threads for the benchmark. Default is 2.
You can check, how much data throughput your server can handle, based on the number of threads with the following command:
elastic_blockchain_proxy verify-cpu-bench
Besides these parameters, additional configuration entries are
available in the $config-dir/elastic_blockchain_proxy.toml file
and in the $config-dir/elastic_blockchain_proxy_fields.toml file.
The $config-dir/elastic_blockchain_proxy.toml file contains
the following configuration entries:
logger:
level: The Logger level filter; valid values are trace, debug, info, warn, and error. The logger level filter can specify a list of comma separated per-module specific levels, for example: warn,elastic_blockchain_proxy=debug
failure_max_retries: A predefined maximum amount of retry attempts. A value of 0 means that no retries will be attempted.
failure_sleep_ms_between_retries: A fixed amount of milliseconds to sleep between each retry attempt
data_dir: The path to the folder that contains the
key.jsonfile. If the file is not present, EL PROXY will generate one when needed.data_backup_dir: The path where the EL PROXY creates a backup copy of the automatically generated keys. for security reasons, the user is in charge of moving these copies to a protected place as soon as possible.
dlq_dir: The path where the Dead Letter Queue with the failed logs is saved.
message_queue_size: The size of the in-memory queue where messages will be stored before while waiting for being processed
web_server:
address: The address where the El Proxy Web Server will listen for HTTP requests
tls: TLS options to enable HTTPS (See the
Enabling TLSsection below)
elasticsearch:
url: The URL of the ElasticSearch server
timeout_secs: the timeout in seconds for a connection to Elasticsearch
ca_certificate_path: path to CA certificate needed to verify the identity of the Elasticsearch server
auth: The authentication method to connect to the ElasticSearch server (See the
Elasticsearch authenticationsection below)
The $config-dir/elastic_blockchain_proxy_fields.toml file contains
the following configuration entries:
include_fields: List of fields of the log that will be included in the signature process. Every field not included in this list will be ignored. The dot symbol is used as expander processor; for example, the field “name1.name2” refers to the “name2” nested field inside “name1”.
Secure Communication¶
When installed on NetEye, the El Proxy automatically starts in secure mode using TLS and also authentication with Elasticsearch is protected by certificates. More precise information for advanced users, who can check the location of the configuration files or modify the setup can be found by checking section El Proxy Security.
Handling Logs in Dead Letter Queue¶
Logs which could not be indexed in Elasticsearch are written in the Dead Letter Queue (DLQ) of the El Proxy.
Since events written in the DLQ are not part of the secured blockchain indices, the NetEye Administrator needs to explicitly acknowledge the presence of the events in the DLQ.
As soon as any log ends up in the DLQ, the Icinga2 service logmanager-blockchain-creation-neteyelocal will enter in CRITICAL state, indicating that some log could not be indexed in the blockchain.
To acknowledge the presence of logs in the DLQ the NetEye admin must:
Ensure that the logs in the DLQ do not contain any sign of malicious activities.
To do so, please inspect the content of the DLQ log files
/neteye/shared/elastic-blockchain-proxy/data/dlq/<customer>/<filename>, where <customer> is the name of the customer who generated the log, and <filename> is the name of the log file.Move all the DLQ log files
/neteye/shared/elastic-blockchain-proxy/data/dlq/<customer>/<filename>in the path/neteye/shared/elastic-blockchain-proxy/data/archive/<customer>/<filename>Hint
To move all the DLQ files in the archive folder you can execute the following CLI commands:
mkdir /neteye/shared/elastic-blockchain-proxy/data/archive/ mv /neteye/shared/elastic-blockchain-proxy/data/dlq/* /neteye/shared/elastic-blockchain-proxy/data/archive/
Acknowledging corruptions of a blockchain¶
The correct state of a blockchain can be checked by executing the verify command, which provides, at the end of its execution, a report about the correctness of the inspected subject. If everything is fine, the verification process will complete successfully, otherwise, the execution report will contain a list of all errors encountered. For example:
--------------------------------------------------------
--------------------------------------------------------
Verify command execution completed.
Blockchain verification process completed with 2 errors.
--------------------------------------------------------
Errors detail:
--------------------------------------------------------
Error 0 detail:
- Error type: Missing logs
- Missing logs from iteration 2 (inclusive) to iteration 4 (inclusive)
- CorruptionId: eyJmcm9tX2l0ZXJhdGlvbiI6MiwidG9faXRlcmF0aW9uIjo0LCJwcmV2aW91c19oYXNoIjoiZGFkNGEwMzMyYTQ1OGZiMzU4OTlmYWQxOTIzYzliNGE1MjZmNzFmZmNmMmU5ZjkxMTExN2I1MTMyMzBkMmFjYyIsImFja25vd2xlZGdlX2Jsb2NrY2hhaW5faWQiOiJhY2tub3dsZWRnZS1lbHByb3h5c2lnbmVkLW5ldGV5ZS1vbmVfd2Vlay0wIn0=
--------------------------------------------------------
Error 1 detail:
- Error type: Wrong Log Hash
- Failed iteration_id: 16
- Expected hash: 34f5bd40d5042ba289d4c5032c75a426306a57e41c0703df4c7698df104f75ed
- Found hash : 593bcd654fd80091105a21f548c1e6a8dd07c80380e72ceeeb1a3e7b126d26bb
- CorruptionId: eyJmcm9tX2l0ZXJhdGlvbiI6MTYsInRvX2l0ZXJhdGlvbiI6MTYsInByZXZpb3VzX2hhc2giOiIwNTE0YmY3YTBmNmRmNmNhMjg1YTIwYTM2OGFiNTA5M2I5NjgxMWZkZWFmMmQ1YThhYjFkOTYwYzgyNDRiNzJlIiwiYWNrbm93bGVkZ2VfYmxvY2tjaGFpbl9pZCI6ImFja25vd2xlZGdlLWVscHJveHlzaWduZWQtbmV0ZXllLW9uZV93ZWVrLTAifQ==
--------------------------------------------------------
--------------------------------------------------------
Each error found is provided with a CorruptionId that uniquely identifies it. The CorruptionId is a base64 encoded JSON that contains data to identify a specific corruption of a blockchain.
If required, an admin can fix a corruption by acknowledging it through the acknowledge command. This command will create an acknoledgement for a specific CorruptionId so that, when the verify is again executed, the linked error in the blockchain will be considered as resolved.
For example, we can acknowledge the first error reported in the above example with:
elastic_blockchain_proxy acknowledge --key-file /path/to/secret/key --corruption-id=eyJmcm9tX2l0ZXJhdGlvbiI6MiwidG9faXRlcmF0aW9uIjo0LCJwcmV2aW91c19oYXNoIjoiZGFkNGEwMzMyYTQ1OGZiMzU4OTlmYWQxOTIzYzliNGE1MjZmNzFmZmNmMmU5ZjkxMTExN2I1MTMyMzBkMmFjYyIsImFja25vd2xlZGdlX2Jsb2NrY2hhaW5faWQiOiJhY2tub3dsZWRnZS1lbHByb3h5c2lnbmVkLW5ldGV5ZS1vbmVfd2Vlay0wIn0=
The acknowledgement data is persisted in a dedicated Elasticsearch index whose name is
generate from the name of the index to which the corruption belong. For example, if the
corrupted index name is *-*-elproxysigned-neteye-one_week-0-*, then the name of the
acknowledge blockchain will be acknowledge-elproxysigned-neteye-one_week-0.
How to setup the automatic verification of blockchains¶
This chapter illustrates the best practices for the setup of a secure and automatic verification of the El Proxy blockchains. We will setup an environment where the verification of a specific blockchain is performed every day. Moreover we will describe how we can notify the failure (and the success) of the blockchain verification in Icinga 2 via Tornado Webhook Collectors and Tornado rules.
This guide is organized as follows: we first introduce the Prerequisites, then we describe the Client and NetEye setup. Finally we provide a few commands for Testing the configuration.
In the remainder we will use the following naming convention:
<tenant>: The tenant (also referred to as “customer” in the previous chapters) of the blockchain that needs to be verified
<retention>: the retention of the blockchain to be verified
<tag>: the tag of the blockchain to be verified
<webhook_token>: a secret string chosen as token for the Tornado Webhook Collector
<webhook_collector_host>: the FQDN of the host where your Tornado Webhook Collector will run. It may be the NetEye Master or a NetEye Satellite FQDN.
Note
While following this guide and executing commands, remember to always substitute the placeholders <…> with their real value.
Prerequisites¶
You have the file containing the initial key of the blockchain to be verified
The verification automatism needs to be set up on a machine which is external to the NetEye installation which is accessible only by you. The external machine must run a CentOS 7 distribution and needs to reach:
The NetEye Master on port 9200 for contacting Elasticsearch.
The <webhook_collector_host> on port 443 to connect to the Tornado Webhook Collector.
Client Setup¶
Add the FQDN of the NetEye Master in the
/etc/hostsfile of the external machineInstall the client to verify blockchain from the external machine
Create a new repository definition by creating the file
/etc/yum.repos.d/CentOS-NetEye.repoSet its content to:
#NetEye packages [neteye] name=CentOS7-x86_64 - NetEye baseurl=https://repo.wuerth-phoenix.com/centos7-x86_64/RPMS.neteye-$YUM0 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-NETEYE enabled=0 priority=1
Copy the GPG Key to verify NetEye RPMs:
From the NetEye Master or a NetEye Satellite copy the file
/etc/pki/rpm-gpg/RPM-GPG-KEY-NETEYEand save it in/etc/pki/rpm-gpg/RPM-GPG-KEY-NETEYE
Install the RPM
elastic-blockchain-proxyby executing:
export YUM0=<neteye_version> yum clean metadata --enablerepo=neteye yum install elastic-blockchain-proxy --enablerepo=neteye
Note
Set
<neteye_version>to the version of NetEye in use. For example setexport YUM0=4.22Point the El Proxy verification client to the Elasticsearch of the NetEye Master
Edit the file
/neteye/shared/elastic-blockchain-proxy/conf/elastic_blockchain_proxy.tomland set the entryurlunder the sectionelasticsearchto the NetEye Master FQDN. For example set:
[elasticsearch] #ElasticSearch URL url = "https://<neteye_master_fqdn>:9200"
Move the initial signature key file of the blockchain to be verified in a secure path in the Filesystem of the external machine.
If not moved previously, you can find the initial signature key on NetEye, in the path:
/neteye/shared/elastic-blockchain-proxy/data/keys_backup/<tenant>/elproxysigned-<tenant>-<retention>-<tag>_key.jsonMove initial signature key file on the external machine in the path:
/root/elastic-blockchain-proxy/keys/elproxysigned-<tenant>-<retention>-<tag>.jsonFor security reasons restrict the permissions on the signature key file:
chown root:root /root/elastic-blockchain-proxy/keys/elproxysigned-<tenant>-<retention>-<tag>.json chmod 400 /root/elastic-blockchain-proxy/keys/elproxysigned-<tenant>-<retention>-<tag>.json
Get the Elasticsearch client certificates needed to verify the blockchain of your <tenant>:
Access one of the NetEye satellites of the NetEye Tenant <tenant> (in case of the
mastertenant, access the NetEye Master machine)Note
If for any reason the tenant of the blockchain does not correspond to any of the NetEye tenants, you need to create new client certificates for a new user along with its Role from Kibana and its Role Mapping. The role should grant read permission to the indices
*-elproxysigned-<tenant>-*and the role mapping should assign the aforementioned role to a user named as the CN of the certificate.Check for the presence of the client certificates
If you are on a NetEye Satellite check for the presence of:
/neteye/local/elasticsearch/conf/certs/ebp_verify.crt.pem/neteye/local/elasticsearch/conf/certs/private/ebp_verify.key.pem
If you are on the NetEye Master check for the presence of:
/neteye/local/elasticsearch/conf/certs/neteye_ebp_verify_master.crt.pem/neteye/local/elasticsearch/conf/certs/private/neteye_ebp_verify_master.key.pem
Copy the certificates on the external machine, in the paths:
/root/elastic-blockchain-proxy/certs/ebp_verify.crt.pem/root/elastic-blockchain-proxy/certs/private/ebp_verify.key.pem
Install the NetEye CA on the external machine:
The NetEye CA certificate file can be found in
/neteye/local/elasticsearch/conf/certs/root-ca.crton the NetEye Master or on one of the NetEye SatellitesCopy the NetEye CA in the El Proxy
certsdirectory of the external machine:mkdir -p /neteye/shared/elastic-blockchain-proxy/conf/certs/ scp root@<neteye_master/neteye_satellite>:/neteye/local/elasticsearch/conf/certs/root-ca.crt /neteye/shared/elastic-blockchain-proxy/conf/certs/
Create a systemd timer which will trigger the blockchain verification process:
Create the file
/etc/systemd/system/elproxy_verify_<tenant>_<retention>_<tag>.timerSet the file content to:
[Unit] Description=Trigger the verification of El Proxy blockchain [Timer] OnCalendar=daily Persistent=true [Install] WantedBy=timers.target
Create a script containing the code to execute the verification and send the result to a Webhook Collector
Create the file
/usr/local/bin/elproxy_verify_blockchain_and_send_resultMake it executable
chmod 750 /usr/local/bin/elproxy_verify_blockchain_and_send_result
Set its content to:
#!/bin/sh TENANT="$1" RETENTION="$2" TAG="$3" WEBHOOK_COLLECTOR_HOST="$4" WEBHOOK_TOKEN="$5" /usr/bin/elastic_blockchain_proxy verify --key-file "/root/elastic-blockchain-proxy/keys/elproxysigned-${TENANT}-${RETENTION}-${TAG}_key.json" --index-name "*-*-elproxysigned-$TENANT-$RETENTION-$TAG-*" --elasticsearch-authentication-method pemcertificatepath --elasticsearch-client-cert /root/elastic-blockchain-proxy/certs/ebp_verify.crt.pem --elasticsearch-client-private-key /root/elastic-blockchain-proxy/certs/private/ebp_verify.key.pem /usr/bin/curl "https://$WEBHOOK_COLLECTOR_HOST/tornado/webhook/event/elproxy_verification?token=$WEBHOOK_TOKEN" -d "{\"exit_status\": \"$?\"}"
Note
To successfully verify the HTTPS server certificate of the <webhook_collector_host> the external machine needs to trust at system level the server certificate CA. To find the CA in use on the <webhook_collector_host> you can refer to NetEye Master HTTPS configuration or NetEye Satellite HTTPS configuration, depending on the <webhook_collector_host> node type.
Please feel free to adapt the script to your necessities.
Create a systemd service which will actually handle the blockchain verification
Create the file
/etc/systemd/system/elproxy_verify_<tenant>_<retention>_<tag>.serviceSet the file content to:
[Unit] Description=Verify El Proxy blockchain Wants=elproxy_verify_<tenant>_<retention>_<tag>.timer [Service] Type=oneshot ExecStart=/usr/local/bin/elproxy_verify_blockchain_and_send_result "<tenant>" "<retention>" "<tag>" "<webhook_collector_host>" "<webhook_token>" [Install] WantedBy=multi-user.target
Reload the systemd configuration:
systemctl daemon-reloadEnable the systemd timer:
systemctl enable elproxy_verify_<tenant>_<retention>_<tag>.timer
NetEye Setup¶
Configure a Tornado Webhook Collector (executable) on either the NetEye Master, or a NetEye Satellite. This Webhook Collector will take care of receiving the El Proxy blockchain verification result from the external machine and forward it to Tornado, which will set an Icinga 2 status.
On the node where the Tornado Webhook Collector is running, create the file
/neteye/shared/tornado_webhook_collector/conf/webhooks/elproxy_verification.jsonSet its content to:
{ "id": "elproxy_verification", "token": "<webhook_token>", "collector_config": { "event_type": "elproxy_verification", "payload": { "data": "${@}" } } }
Restart the Tornado Webhook Collector service to load the webhook
Configure a Rule in Tornado to set a status in Icinga 2
Via NetEye Tornado GUI, create a Rule that matches the Events with type
elproxy_verificationand executes an Action of type SMART_MONITORING_CHECK_RESULT, where we set ascheck_result -> exit_statusthe valueevent.payload.data.exit_status. Configure the rest of the Rule as you prefer.
Testing the configuration¶
Now everything should be configured correctly. To test your configuration you can:
Force the verification service to start with:
systemctl start elproxy_verify_<tenant>_<retention>_<tag>.service
Inspect the logs of the verification service with:
journalctl -u elproxy_verify_<tenant>_<retention>_<tag>.service -f
Agents configuration¶
Installation and Configuration of Beat Agents¶
Before being able to take fully advantage of the Beat feature, agents
must be installed on the monitored hosts, along with the necessary
certificates. On the hosts, any kind of Beat can be installed; for
example, the Winlogbeat is available from the official download
page;
installation
instructions
are available as well. The agent configuration is stored in the YAML
configuration file winlogbeat.yml. A description of the options
available in the Beat’s configuration file can be found in the official
documentation.
Note
You need to install a Beat whose version is compatible with the Elastic version installed on NetEye, which is 7.15. To find out which version of Beat you can install, please check the compatibility matrix
Relevant to the configuration are the following options:
ignore_older, which indicates how many hours/days it should gather data from. By default, indeed, the Beat collects all the data it finds, meaning it can act retroactively. This is the default option if not specified, so make sure to properly configure this option, to not overload the initial import of data and to avoid potential problems like crash of Logstash and ES disk space.
index: ”winlogbeat”, which is needed to match NetEye’s templates and ILM.
Filebeat Netflow module specific configuration¶
In NetEye, Filebeat is shipped with the NetFlow
Module
included.
The module can be configured without directly modifying the configuration file,
avoiding so rpmnew files and the reactivation of the module during future updates,
since it is enabled by default.
This can be accomplished by setting the following three environment
variables in the /neteye/shared/filebeat/conf/sysconfig/filebeat-user-customization
environment file:
NETFLOW_ENABLED: which can be used to enable or disable the listening of logs on the specified host and port. Default: true
NETFLOW_HOST: The host to which the module will listen on. Default: 0.0.0.0 (all hosts)
NETFLOW_PORT: The port to listen on. Default: 2055
After changing the value of any of the aforementioned variables, a restart of the filebeat service must be performed by running:
neteye# systemctl restart filebeat
Warning
If the module is deactivated using the filebeat modules disable command and not using the associated environment variable, Filebeat will rename the configuration file and, at the next update, the module will be re-installed and re-activated.
Use of SSL certificates¶
Server certificates of Logstash allowing communication with Beats must
be stored in the /neteye/shared/logstash/conf/certs/ directory, with
names logstash-server.crt.pem and private/logstash-server.key.
Additionally, also the root-ca.crt certificate must be available in
the same directory.
The structure mentioned above for the certificates must be organised as:
certs/
├── logstash-server.crt.pem
├── root-ca.crt
└── private/
└── logstash-server.key
The certificates are stored under the logstash configuration
directory, because it is indeed Logstash that listens for incoming Beat
data flows.
As a consequence, all Beat clients must use a client certificate to send output data to Logstash. Please refer to the Elastic official documentation, for example the Filebeat SSL configuration is available here.
An example of Filebeat to Logstash SSL communication configuration is the following:
#--------- Logstash output ------------------------------------
output.logstash:
# The Logstash hosts
hosts: ["yourNetEyeDomain.example:5044"]
# List of root certificates for HTTPS server verifications
ssl.certificate_authorities: ["/root/beat/root-ca.crt"]
# Certificate for SSL client authentication
ssl.certificate: "/root/beat/logstash-client.crt.pem"
# Client Certificate Key
ssl.key: "/root/beat/private/logstash-client.key.pem"
Self-signed certificates¶
Note
For production systems, you should upload your own certificates on NetEye. Moreover, you should use your own certificates also for all Beat clients. Self-signed certificates must never be used on production systems, but only for testing and demo purposes.
Self-signed certificates (logstash-server.crt.pem and private/logstash-server.key) and the Root CA (root-ca.crt) are shipped with NetEye for Logstash. Self-signed certificates for Beat clients can be generated from the CLI as follows:
- you can run the script
usr/share/neteye/scripts/security/generate_client_certs.shusing three suitable parameters: The client name
The common name (CN) and information for the other certificate’s field
The output directory
An example of command line is the following:
/bin/bash /usr/share/neteye/scripts/security/generate_client_certs.sh \
logstash-client \
"/CN=logstash-client/OU=client/O=client/L=Bolzano/ST=Bolzano/C=IT" \
"/root/beat/"
Inputs configuration¶
To set customer-specific filebeat inputs you can add a file with .yml extension in the directory
/neteye/shared/filebeat/conf/inputs.d/.
Configuration will be read and applied from .yml files only: any file with different extension will be ignored.
To maintain a custom configuration saved but disabled, you should rename the file with a different extension,
for example mqtt.yml can be disabled by renaming it to mqtt.yml.disable.
A sample configuration can be found in file /neteye/shared/filebeat/conf/inputs.d/mqtt.yml.sample.
Event Processing¶
Logstash Configuration¶
We have added an Elastic Stack template which allows us to manage the Logstash configuration within the NetEye environment.
Please note that Elastic merges all templates using a priority order scheme so that when the values of multiple templates conflict, Elastic will determine which value to use based on the “order” field in the template. The higher the value, the higher the priority.
Furthermore, please note how all pipelines configuration files, located in the /neteye/shared/logstash/conf/conf.*.d
folders, are set as config files, which prevents them from being silently overwritten
by future updates. As mentioned also in the .rpmsave and .rpmnew migration guide,
config files will instead lead to an rpmnew file if they were modified both on the system
and by the update, enabling so the user to control their migration.
Autoexpand Replicas¶
We created a Logstash template to configure the Logstash replica that applies to both single instances and clusters. The new indices matching the pattern logstash-* will automatically configure the replica with the range 0-1 using the index.auto_expand_replicas setting.
The name of this template is neteye_logstash_replicas, with a priority order of 100. You can view the full template with the following command:
GET _template/neteye_logstash_replicas
Enabling El Proxy¶
The El Proxy receives streams of log files from Logstash, signs them in real time into a blockchain, and forwards them to Elasticsearch. For more information, please check section El Proxy
To make the use of the El Proxy easier, different default pipelines, called input_beats, auditbeat, filebeat, winlogbeat and ebp_persistent pipelines have been provided. The input_beats pipeline redirects logs to main or to the beat specific pipelines (auditbeat, filebeat, winlogbeat). If the El Proxy is enabled for a specific host and the log matches the conditions specified in the beat specific pipelines, logs will also be redirected to ebp_persistent pipeline.
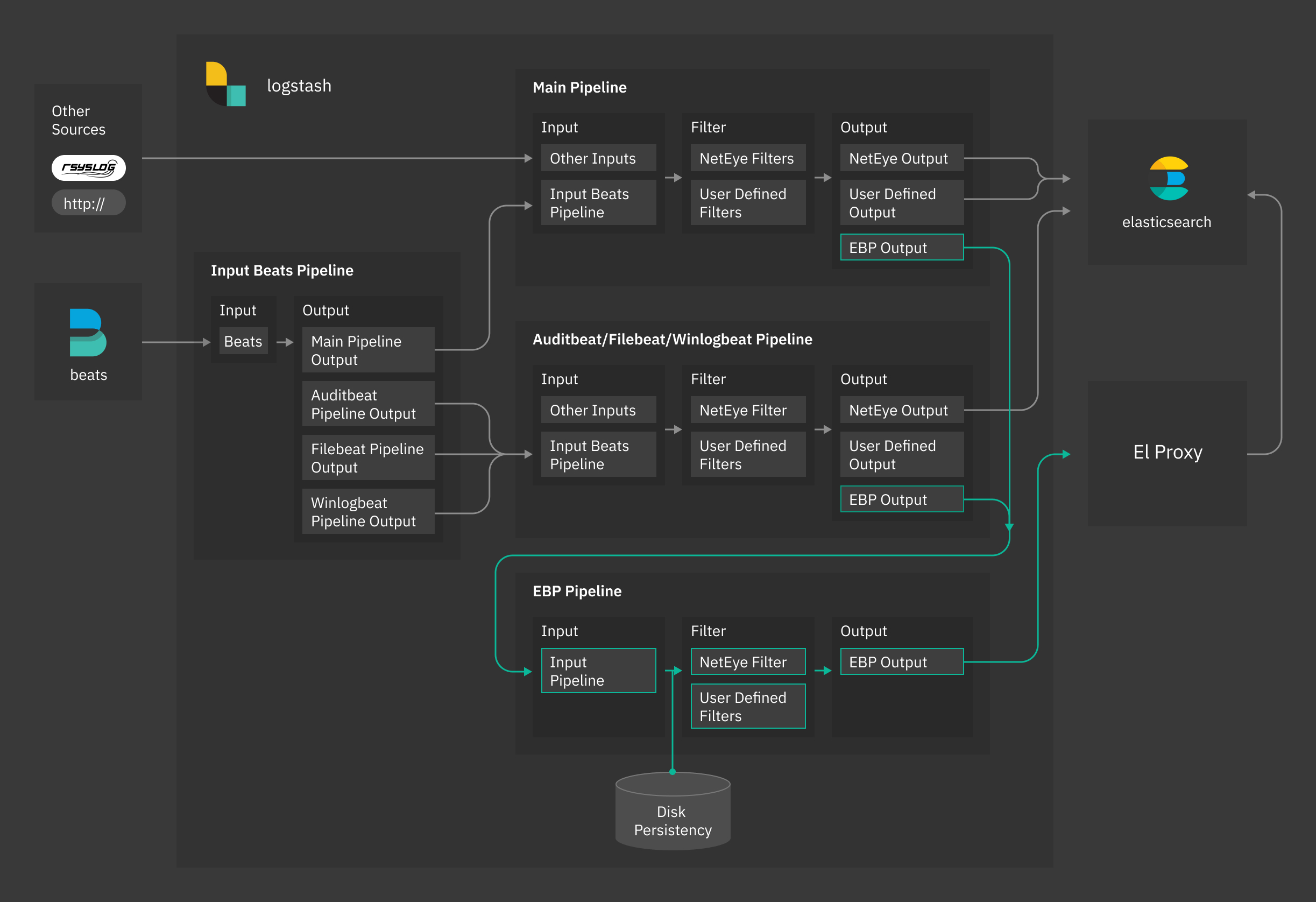
Fig. 163 NetEye Logstash El Proxy architecture¶
Specifically, the ebp_persistent pipeline enables disk persistency, extracts client certificate details and redirects data to the El Proxy.
Please note that you need to have enough space in /neteye/shared/logstash/data/ for disk persistency.
The ebp_persistent pipeline is configured with three parameters:
queue.type: specify if the queue is in memory or disk-persisted. If set topersistedthe queue will be disk-persisted.
path.queue: the path where the events will be persisted, by default/neteye/shared/logstash/data/ebp
queue.max_bytes: the maximum amount of data the queue can write, by default512mb. Exceeding this limit may lead to a loss of events.
You can check and adjust the parameters for the queue in the file
/neteye/shared/logstash/conf/pipelines.yml.
The user can customize the ebp_persistent pipeline by adding custom Logstash filters in the form of .filters
files in the directory /neteye/shared/logstash/conf/conf.ebp.d.
Please note that the user must neither add .input or .output files nor modify existing configuration files.
Warning
Enabling the El Proxy via the variable
EBP_ENABLED in the file /neteye/shared/logstash/conf/sysconfig/logstash-user-customization
is not anymore supported. Please enable it per host as described below.
El Proxy can be enabled per host via Icinga Director. A Host Template, called logmanager-blockchain-host is made available for this purpose.
To enable El Proxy on a host (we’ll call the host ACME), we strongly suggest to first create a dedicated host template, which imports logmanager-blockchain-host. Then, configure the host ACME to inherit from this host template.
You can refer to Sections Host Templates and to Adding a Host for further information about how to manage host templates and hosts in the Icinga Director.
As soon as you use the new dedicated template, the following fields are shown in the Host Configuration Panel under Custom properties:
Enable Logging: specify if logging for the current host must be enabled. If set toYeslog collection is enabled.
Blockchain Enable: it appears only ifEnable Loggingis enabled. Specify if the log signature must be enabled for the current host. If set toYes, El Proxy is enabled for the host.
Blockchain Retention: it becomes available only ifBlockchain Enableis enabled. The retention policy specified for the logs of the current host (default value is 2 years or 730 days). Refer to Section El Proxy Templates and Retention for further information on retention policies.
Note
Enable Logging works in combination with Blockchain Enable, both properties must
be set to Yes to fully enable the log collection and the log signing.
Log and Blockchain properties of a hosts are regularly checked by the logmanager-director-es-index-neteyelocal service, which automatically stores them in Elasticsearch where they can be queried and accessed when needed.
For additional information about El Proxy refer to section El Proxy.
By default, El Proxy uses the common name (CN) specified in the Beats certificate as the customer name.
If the CN is not available, El Proxy uses a default customer name as a fallback.
The user can configure a custom default customer name by setting the variable EBP_DEFAULT_CUSTOMER
in the file /neteye/shared/logstash/conf/sysconfig/logstash-user-customization,
as follows:
EBP_DEFAULT_CUSTOMER="mycustomer"
If the variable EBP_DEFAULT_CUSTOMER is not set, El Proxy will use the value “neteye” as default customer.
You must restart Logstash for the changes to take effect.
For additional information about El Proxy refer to El Proxy
El Proxy Templates and Retention¶
We have added a template called elastic_blockchain_proxy to define static and dynamic mapping for El Proxy objects EBP_METADATA and ES_BLOCKCHAIN. The user must not change the mapping of El Proxy related fields.
Several ILM (Index Lifecycle Management) policies are provided by default and should cover most of the use cases. Policies come alongside with index templates and are applied by default to indices matching the pattern *-elproxysigned-*-retention_name-*.
Do not change default templates or ILM policies because they will be automatically overwritten.
Default retention policies are:
3_months: delete index after 90 days from creation
6_months: delete index after 180 days from creation
1_year: delete index after 365 days from creation
2_years: delete index after 730 days from creation
default: delete index after 730 days from creation
infinite: do not delete the index
To specify which ILM policy to use you can set the field EBP_METADATA.retention in a logstash filter.
For example, if you want to set a 6 months policy for authentication logs you can create a new filter
in the directory /neteye/shared/logstash/conf/conf.ebp.d called 1_f10000_auth_retention.filter
which contains the following condition:
filter {
if "authentication" in [event][category] {
mutate {
replace => {"[EBP_METADATA][retention]" => "6_months" }
}
}
}
If the index pattern does not match any valid retention policy name a 2-years ILM policy will be applied.
Changing the retention policy for an existing blockchain results in the creation of a new blockchain: a new key will be generated and must be saved in a safe place. All new logs will be saved in the new blockchain while the old blockchain will not receive any new log. For the verification process you need to use the appropriate key for each blockchain.
The retention policy change is not retroactive: the old blockchain will maintain the original retention period.
To create a custom retention policy you have to:
Create a new ILM policy
Create a new index template to apply the new ILM policy e.g.:
{ "order": 150, "index_patterns": [ "*-elproxysigned-*-my_retention-*" ], "settings": { "index": { "lifecycle": { "name": "my_ilm_policy" } } } }
You must never change the deletion period with a shorter one otherwise you will have missing logs in the middle of the blockchain and this will cause the verification to fail.
Sending custom logs to El Proxy¶
By default only Beats events are sent to El Proxy, if enabled. NetEye, however, provides an output also in the main pipeline to redirect events to the El Proxy.
Events are sent to El Proxy when field [EBP_METADATA][event][module] is set to elproxysigned.
For example, to send all syslog logs to the El Proxy, you can use a filter similar to the
following
filter {
if [type] == "syslog" {
if [EBP_METADATA][event][module] {
mutate {
replace => {"[EBP_METADATA][event][module]" => "elproxysigned"}
}
} else {
mutate {
add_field => {"[EBP_METADATA][event][module]" => "elproxysigned"}
}
}
}
}
All logs passed through the ebp_persistent pipeline will be disk-persisted.
Backup & Restore¶
Elasticsearch Backup and Restore¶
Elasticsearch provides snapshot functionality which is great for backups because they can be restored relatively quickly.
- The main features of Elasticsearch snapshots are:
They are incremental
They can store either individual indices or an entire cluster
They can be stored in a remote repository such as a shared file system
The destination for snapshots must be a shared file system mounted on each Elasticsearch node.
Deleting a snapshot only changes those files that are associated with the deleted snapshot and are not used by any other snapshots. If the deleted snapshot operation is executed while the snapshot is being created, the snapshot process will be aborted and all files created as part of the snapshot process will be removed.
For further details see the Official Elasticsearch snapshot documentation.
Requirements¶
The snapshot module requires the initialization of a repository which contains a reference to a repository path contained in the Elasticsearch configuration file:
/neteye/local/elasticsearch/conf/elasticsearch.yml
This repository, and consequently the destination path for the snapshot, must be initialized manually.
A shared folder must be mounted on each Elasticsearch node at the following path:
/data/backup/elasticsearch
Note
In a cluster environment, all nodes running Elasticsearch must have the same shared folder mounted.
Backup strategy¶
The standard behavior of the Elasticsearch snapshot module is to create incremental backups. You may however want to have full backups in addition to incremental backups. Considering that a full backup is not natively supported, the recommended procedure is to create a new repository for each full backup you need.
Note that in an Elasticsearch cluster installation, all commands must be executed on the Elasticsearch master node. The master node can be retrieved with the following command:
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -M
The following subsections describe the common operations needed to initialize a repository, and to execute, delete and restore snapshots.
Initialize the default repository¶
The initialization uses the following default mount path:
/data/backup/elasticsearch
In a cluster environment it is mandatory to mount the path on a shared file system for each node:
# The default neteye_log_backup repository will be used
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -I
Initialize a new repository, or one different from the default¶
If the new repository uses a custom folder, its path must be added to the Elasticsearch configuration file. In particular, the option “path.repo” in the configuration file:
/neteye/local/elasticsearch/conf/elasticsearch.yml
must be an array containing all destination paths for the snapshot. For instance:
path.repo: ["/data/backup/elasticsearch", "/data/full_backup/"]
Note that if you change the Elasticsearch configuration file, you must restart it:
systemctl restart elasticsearch
You can create a new repository with the name “my_repo” and a custom backup path with this script (if the -r option is not specified, the default neteye_log_backup will be used):
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -r "my_repo" -i /data/full_backup/
Take a snapshot¶
When using a default name: snapshot-Year-Month-Day-Hour:Minute:Second
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -s
When using a custom name (in this example, “test-snapshot”):
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -S test-snapshot
Delete a snapshot¶
You can delete one or more snapshots with a regex. In the example here, only the snapshot with the name “test-snapshot” will be removed:
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -d "test-snapshot"
You can also delete any snapshots that are older than the specified period using the format YY.MM.DD.HH.MM (e.g., 0.1.1.0.0 means 31 days). For more details, see the description of unit.
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -c 0.1.1.0.0
These two options can be combined, for instance to delete all snapshots that contain “test” in the name and that are older than 1 minute:
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -d test -C 0.0.0.0.1
Create a full snapshot¶
A new repository (see the previous section) or an empty repository must be used.
/usr/share/neteye/backup/elasticsearch/elasticsearch-backup -r "my_full_backup" -s
Restoring a snapshot¶
Restoring a snapshot requires a configuration file that describes the process. Please see the official guide for more details. We have provided three example configurations in the following folder::
/usr/share/neteye/backup/elasticsearch/conf
These can be invoked with the following script:
/usr/share/neteye/backup/elasticsearch/elasticsearch-restore -c <absolute-config-file-path>
Restore the last snapshot¶
Restore all indices in the most recent snapshot.
actions:
1:
action: restore
options:
# May be changed according to your setup
repository: neteye_log_backup
# If the name is blank, the most recent snapshot by age will be selected
name:
# If the indices are blank, all indices in the snapshot will be restored
indices:
include_aliases: False
ignore_unavailable: False
include_global_state: False
partial: False
wait_for_completion: True
filters:
filtertype: none
Restore some indices¶
Restore indices with the name provided in indices in the most recent snapshot with state SUCCESS. The indices option supports multiple indices syntax.
In the following example, all the indices starting with “test-” will be restored.
actions:
1:
action: restore
description:
options:
# May be changed according to your setup
repository: neteye_log_backup
# If the name is blank, the most recent snapshot by age will be selected
name:
indices: [test-*]
include_aliases: False
ignore_unavailable: False
include_global_state: False
partial: False
filters:
filtertype: state
state: SUCCESS
Restore Snapshot Renaming¶
Restore all indices in the most recent snapshot by: - Finding any indices being restored that match the rename_pattern. - Changing the name as described in rename_replacement.
The following example will restore all indices which start with “index_”, but rename it to “restored_index_”. E.g., If you have “index_1”, this will restore “index_1”, but rename it to “restored_index_1”. For additional information, see the documentation.
actions:
1:
action: restore
options:
# May be changed according to your setup
repository: neteye_log_backup
# If the name is blank, the most recent snapshot by age will be selected
name:
# If the indices are blank, all indices in the snapshot will be restored
indices:
include_aliases: False
ignore_unavailable: False
include_global_state: False
partial: False
"rename_pattern": "index_(.*)"
"rename_replacement": "restored_index_$1"
extra_settings:
wait_for_completion: True
filters:
filtertype: none