Cluster¶
The clustering service of NetEye 4 is based on the RedHat 8 High Availability Clustering technologies, including Corosync, Pacemaker, and DRBD, used to set up an HA cluster composed of a combination of operating nodes, Elastic-only nodes, and Voting-only nodes. NetEye cluster is a failover cluster at service level, meaning that it provides redundancy to avoid any downtime or service disruption whenever one node in the cluster goes offline. In such a case, indeed, services are moved to another node if necessary.
Reasons for a node to be offline include–but are not limited to:
A networking issue (failure of a network interface or in the connectivity) which prevents a node to communicate with the other nodes
A hardware or software issue which freezes or blocks a node
A problem with the synchronisation of the data
All the cluster services run on a dedicated network called Corporate Network: every cluster node has therefore two IP addresses: A public one, accessible by the running service (including e.g., SSH), and a private one, used by Corosync, Pacemaker, DRBD, and Elastic-only nodes.
Cluster resources are typically quartets consisting of a floating IP in the Corporate Network, a DRBD device, a filesystem, and a (systemd) service. Fig. 2 shows the general case for High Availability, where cluster services are distributed across nodes, while other services (e.g., Icinga 2, Elasticsearch) handle their own clustering requirements. The remainder of this section details the architecture and implementation of a NetEye cluster.
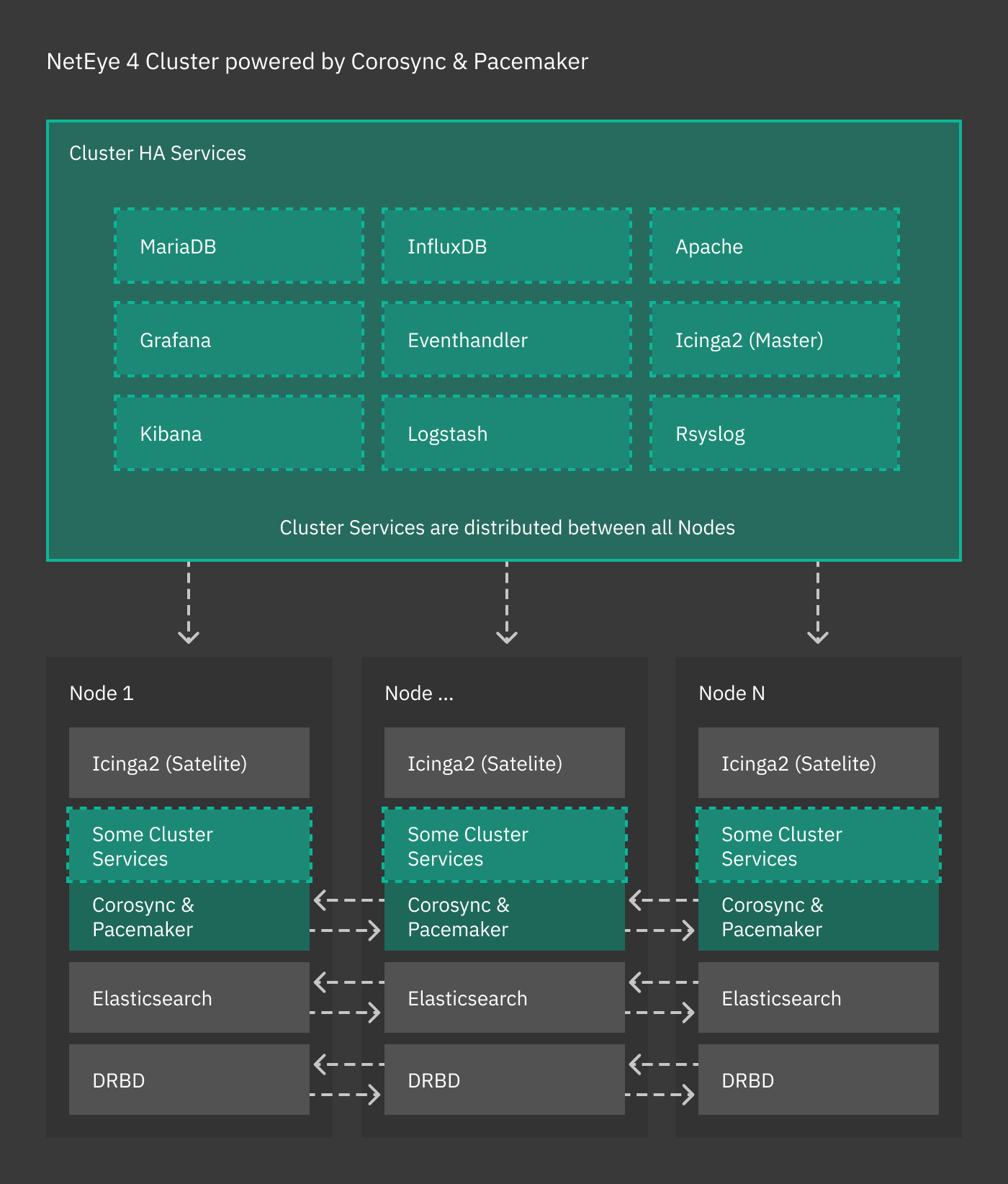
Fig. 2 The NetEye cluster architecture.¶
If you have not yet installed clustering services, please turn to the Cluster Installation page for setup instructions.
Type of Nodes¶
Within a NetEye cluster, different types of nodes can be setup. We distinguish between Operative and Single Purpose nodes, the latter being either Elastic-only or Voting-only nodes. They are
- Operative node
On an operative node runs any services offered by NetEye, like e.g., Tornado, Icinga 2, slmd, and so on. They can be seen as single nodes, connected by the clustering technologies mentioned above.
- Elastic-only node
Elastic-only nodes host only the DB component of the Elastic Stack, while FileBeat, Kibana, and other Elastic Stack components are still clusterised resources and run on operative nodes. Elastic-only nodes are used for either data storage or to add to the cluster more resources and processing abilities of elasticsearch data. In the latter case, the following are typical use cases:
Process log data in some way, for example with Machine Learning tools
Implement an hot-warm-cold architecture
Increase data retention, redundancy, or storage to archive old data
Note
An operative node may also run services of the Elastic Stack, including its DB component. In other words, it is not necessary to have a dedicated node for Elastic services.
- Voting-only node
Nodes of this type are a kind of silent nodes: They do not run any service and therefore require limited computational resources compared to the other nodes. They are needed only in case of a node failure to establish the quorum and avoid cluster disruption.
See also
Voting-only nodes and their use are described with great details in a NetEye blog post: https://www.neteye-blog.com/2020/03/neteye-voting-only-node/
The NetEye Active Node¶
During the update and upgrade operations, it is mandatory that one
of the operative nodes is always active during the procedures. The
nodes of a cluster are listed in the /etc/neteye-cluster file,
for example like the following.
{
"Hostname" : "my-neteye-cluster.example.com",
"Nodes" : [
{
"addr" : "192.168.1.1",
"hostname" : "my-neteye-01",
"hostname_ext" : "my-neteye-01.example.com",
"id" : 1
},
{
"addr" : "192.168.1.2",
"hostname" : "my-neteye-02",
"hostname_ext" : "my-neteye-02.example.com",
"id" : 2
},
{
"addr" : "192.168.1.3",
"hostname" : "my-neteye-03",
"hostname_ext" : "my-neteye-03.example.com",
"id" : 3
},
{
"addr" : "192.168.1.4",
"hostname" : "my-neteye-04",
"hostname_ext" : "my-neteye-04.example.com",
"id" : 4
}
],
"ElasticOnlyNodes": [
{
"addr" : "192.168.1.5",
"hostname" : "my-neteye-05",
"hostname_ext" : "my-neteye-05.example.com",
"id" : 5
}
],
"VotingOnlyNode" : {
"addr" : "192.168.1.6",
"hostname" : "my-neteye-06",
"hostname_ext" : "my-neteye-06.example.com",
"id" : 6
},
"InfluxDBOnlyNodes": [
{
"addr" : "192.168.1.7",
"hostname" : "my-neteye-07",
"hostname_ext" : "my-neteye-07.example.com"
}
]
}
The NetEye Active Node will always be the first node appearing in
the list of Nodes, in this case it is the node with FQDN
my-neteye-01.example.com and it is the one that must always be
active during the update/upgrade procedure.
Therefore, before running neteye update and
neteye upgrade, log in to my-neteye-01.example.com and
make sure that it is not in stand-by mode. To do so, first execute
the command to check the status of the cluster
cluster# pcs status
Then, if my-neteye-01.example.com is in standby, make it active
with command
cluster# pcs node unstandby my-neteye-01.example.com
See also
How nodes are managed by the NetEye update/upgrade commands is described with great details in a NetEye blog post: https://www.neteye-blog.com/2021/10/hosts-and-neteye-upgrade/
Clustering and Single Purpose Nodes¶
The following services use their own native clustering capabilities rather than Red Hat HA Clustering. NetEye will also take advantage of their inbuilt load balancing capabilities.
- Icinga 2 Cluster
An Icinga 2 cluster is composed by one master instance holding configuration files and by a variable number of satellites and agents.
See also
Icinga 2 clusters are described in great detail in the official Icinga documentation
- Elasticsearch
Each cluster node runs a local master-eligible Elasticsearch service, connected to all other nodes. Elasticsearch itself chooses which nodes can form a quorum (note that all NetEye cluster nodes are master eligible by default), and so manual quorum setup is no longer required.
See also
Elastic clusters and Elastic-only nodes are described with more details in the General Elasticsearch Cluster Information section.
- Galera
The Galera cluster is a synchronous multi-master cluster for MariaDB. It is used to provide high availability and redundancy for the MariaDB database service. Each node in the Galera cluster can accept read and write requests, and changes made on one node are automatically replicated to all other nodes in the cluster.
See also
Galera clusters are described in detail in the official Galera documentation.
Warning
When dealing with a Galera cluster, it is important to be aware of the following:
When restarting or starting a Galera node, the systemctl command will wait for the node to fully synchronize with the cluster before completing. This ensures that each node is properly aligned with the current cluster state and has consistent data before becoming operational. This synchronization process may take varying amounts of time depending on how much data needs to be transferred to bring the node up to date with the rest of the cluster.
The Galera cluster uses a quorum-based approach to ensure data consistency and availability. This means that a Galera Cluster will continue operating as long as more than half of the nodes (N/2 + 1) are up and synchronized. If the quorum is lost, the Galera cluster will block all operations to prevent data inconsistency across the cluster.
Node Roles¶
Among the different types of nodes in a cluster, it is possible to assign specific roles to specific NetEye nodes, depending on the customer needs and the node capabilities.
For more information about the node roles, please refer to the Cluster Nodes Roles section.
Clustering Services¶
The combination of the following software is at the core of the NetEye’s clustering functionalities:
Corosync: Provides group communication between a set of nodes, application restart upon failure, and a quorum system.
Pacemaker: Provides cluster management, lock management, and fencing.
DRBD: Provides data redundancy by mirroring devices (hard drives, partitions, logical volumes, etc.) between hosts in real time.
“Local” NetEye services running simultaneously on each NetEye node
( i.e. not managed by Pacemaker and Corosync ), are managed by a
dedicated systemd target unit called
neteye-cluster-local.target. This reduced set of local services
is managed exactly alike the Single Node neteye target:
# systemctl list-dependencies neteye-cluster-local.target
neteye-cluster-local.target
● └─drbd.service
● └─elasticsearch.service
● └─icinga2.service
[...]
Cluster Management¶
There are several CLI commands to be used in the management and troubleshooting of clusters, most notably drbdmon, drbdadm, and pcs.
The first one, drbdmon is used to monitor the status of DRBD, i.e., to verify if the nodes of a cluster communicate flawlessly or if there is some ongoing issue, like e.g., a node or network failure, or a split brain.
The second command, drbdadm allows to carry out administrative tasks on DRBD.
Finally, the pcs command is used to manage resources on a pcs cluster only; its main purpose is to move services between the cluster nodes when required.
In particular, pcs status retrieves the current status of the nodes and services, while pcs node standby and pcs node unstandby put a node offline and back online, respectively.
More information and examples about these command can be found in section Cluster Management Commands.
Self-signed root CA¶
The NetEye install process creates a self-signed root Certificate
Authority in /root/security/. This CA is synchronized
throughout the NetEye Cluster.
The common CA is trusted automatically during installation with neteye install, leveraging the update-ca-trust script to update certificate authorities provided by the system. Once the CA is in place, each module on each cluster node can request its certificate which is then signed by the common CA.
By default, the NetEye CA is stored in /root/security/ and trust
settings are set in /usr/share/pki/ca-trust-source/. That directory
contains CA certificates and trust settings in the PEM file format, and
these are interpreted as a default priority. This setting allows the
administrator to override the CA certificate list. Of course, for
correct trust behavior, the NetEye CA should not be overwritten.
Certificates Storage¶
Each component that uses certificates, stores them in its conf
folder, under the directory certs.
For example, Elasticsearch stores the certificates in the path
/neteye/local/elasticsearch/conf/certs/
The certs folder contains the public certificates, while the private
keys are stored inside certs/private/.
For example, the public certificate of the Elasticsearch admin is stored in
/neteye/local/elasticsearch/conf/certs/admin.crt.pem, while its private key is stored in/neteye/local/elasticsearch/conf/certs/private/admin.key.pem
Some components export the certificates in PKCS 12 bundles (.pfx
files) inside the folder certs/private/. These bundles contain the
private key together with its corresponding certificate. If not
differently specified, the password to decrypt the pfx files is
blank (i.e. empty password).
For example, Tornado exports its certificate and private key to PKCS 12 format inside the file
/neteye/shared/tornado/conf/certs/private/tornado.pfx. This can be decrypted by using an empty password:openssl pkcs12 -in /neteye/shared/tornado/conf/certs/private/tornado.pfx -nodes -password pass:
Secure Intracluster Communication¶
Security between the nodes in a cluster is just as important as front-facing security. Because nodes in a cluster must trust each other completely to provide failover services and be efficient, the lack of an intracluster security mechanism means one compromised cluster node can read and modify data throughout the cluster.
NetEye uses certificates signed by a Certificate Authority to ensure that only trusted nodes can join the cluster, to encrypt data passing between nodes so that externals cannot tamper with your data, and allows for certificate revocation for the certificates of each component in each module.
Two examples of cluster-based modules are:
DRBD, which replicates block devices over the network
The Elastic stack, which the NetEye 4 Log Management is based on.