Architecture¶
Introduction¶
NetEye is a flexible stack of monitoring technologies and can easily be adjusted to serve its purpose under conditions granted by the hosting infrastructure.
NetEye is a scalable and extensible software. Indeed, on the one side, NetEye can be run on a Single Node or Cluster (multiple nodes) architecture, while on the other side you can add Tenants, Satellites or even agents to gather data and send them to the Master for processing, offloading tasks to other devices.
Based on the customer’s monitoring and analytical needs, services can be executed in complex environments across multiple locations, e.g. tracking the state of routers in all the premises and offices of your organization.
A set of services provided by the NetEye may vary depending on whether you choose to utilize core functionality modules that are originally shipped with NetEye, or install additional components in order to perform even more specific tasks, e.g. measure visual end-user experience with the help of the integrated Alyvix software.
Single Node and Cluster Concept¶
Another decisive point while tuning the NetEye architecture to meet your business requirements is the complexity of the processes to be executed.
All the provided services may be scaled by means of adopting an appropriate NetEye setup type. To choose the most appropriate setup type you will need to estimate the expected level of the monitoring system and the amount of resources you’d like to involve in the monitoring process.
In case your target infrastructure is small and requires a minimum amount of resources, running NetEye on a Single Node architecture would be the best solution.
For a more complex environment that requires redundancy and high availability when running monitoring process, it is recommended that you use Cluster setup. Cluster allows to scale the system up to a level where it is able to deal with an extensive amount of resources. At the same time Cluster grants high-availability and helps to avoid any downtime or service disruption whenever one of several nodes in a Cluster goes offline, e.g. in case of a networking or hardware/software issue.
NetEye Master and Multi-tenancy¶
NetEye Master instance serves either as a self-contained server (Single Node), or a high availability Cluster composed of a combination of nodes.
The Master allows to build individual and isolated communications from multiple clients to a centralized server, i.e. the Master, that will then process independently all data streams (see NetEye Master and Multi-tenancy).
Communication between the client and the Master may involve Satellite nodes. Each client is to be monitored independently, so a Satellite would be assigned to each separate set of hosts to collect and communicate their data to the Master for further processing.
Satellites can be set up irrespective of whether you are using NetEye as a Single Node or a Cluster.
The client data may also be transmitted to the Master directly, without involving a Satellite (or multiple Satellites where appropriate) as an actor.
Having received the data, the Master then processes it in order to fulfill predefined tasks, e.g. make data entries to Influx DB, generate a Tornado action based on the event, etc.
NetEye supports multi-tenancy architecture, where a single NetEye instance allows you to serve multiple business units inside your organization(s). Multi-tenancy concept allows you to monitor a number of clients, whether you choose to run monitoring on a Cluster or Single Node architecture.
Having multiple tenants you will be able to aggregate even larger arrays of data, preserving data security: each tenant zone communicates with the Master individually and is not visible for others. Communication of a tenant with the Master can be protected by using multiple accounts.
Single Node¶
NetEye can be run on a Single Node Architecture, i.e. as a self-contained server. Single Node is the basic variation of NetEye setup, and is aimed at small environments that require limited resources. Apart from that, running NetEye on a Single Node architecture is applicable in case your infrastructure does not require high availability. To maintain high availability of a monitoring environment, you should better consider going with Cluster setup.
To start monitoring on a Single Node it only requires to install NetEye, run initial configuration, and begin the actual process: define services, hosts, etc.
A variety of NetEye services may be run on a Single Node installation to fulfill monitoring functionality.
Single Node is a basic setup type, however you can enhance your monitoring environment to a NetEye Cluster and/or set up several tenants to monitor simultaneously. To fulfil the latter, your environment might use Satellite nodes as actors that help communicate data to the Master. Satellite Node is to be set up together with a Single Node, and then configured individually.

Fig. 2 A NetEye Single Node with tenants.¶
NetEye services on a NetEye Single Node installation are managed by
systemd. A single systemd target is a special systemd unit and
is responsible for managing start and stop operations of NetEye
services.
There can be more than one systemd unit available within installation, however only one may be enabled. To find out which NetEye systemd target is currently active, use the following command.
neteye# systemctl list-units "neteye*.target"
Cluster¶
The clustering service of NetEye 4 is based on the RedHat 8 High Availability Clustering technologies, including Corosync, Pacemaker, and DRBD, used to set up an HA cluster composed of a combination of operating nodes, Elastic-only nodes, and Voting-only nodes. NetEye cluster is a failover cluster at service level, meaning that it provides redundancy to avoid any downtime or service disruption whenever one node in the cluster goes offline. In such a case, indeed, services are moved to another node if necessary.
Reasons for a node to be offline include–but are not limited to:
A networking issue (failure of a network interface or in the connectivity) which prevents a node to communicate with the other nodes
A hardware or software issue which freezes or blocks a node
A problem with the synchronisation of the data
All the cluster services run on a dedicated network called Corporate Network: every cluster node has therefore two IP addresses: A public one, accessible by the running service (including e.g., SSH), and a private one, used by Corosync, Pacemaker, DRBD, and Elastic-only nodes.
Cluster resources are typically quartets consisting of a floating IP in the Corporate Network, a DRBD device, a filesystem, and a (systemd) service. Fig. 3 shows the general case for High Availability, where cluster services are distributed across nodes, while other services (e.g., Icinga 2, Elasticsearch) handle their own clustering requirements. The remainder of this section details the architecture and implementation of a NetEye cluster.
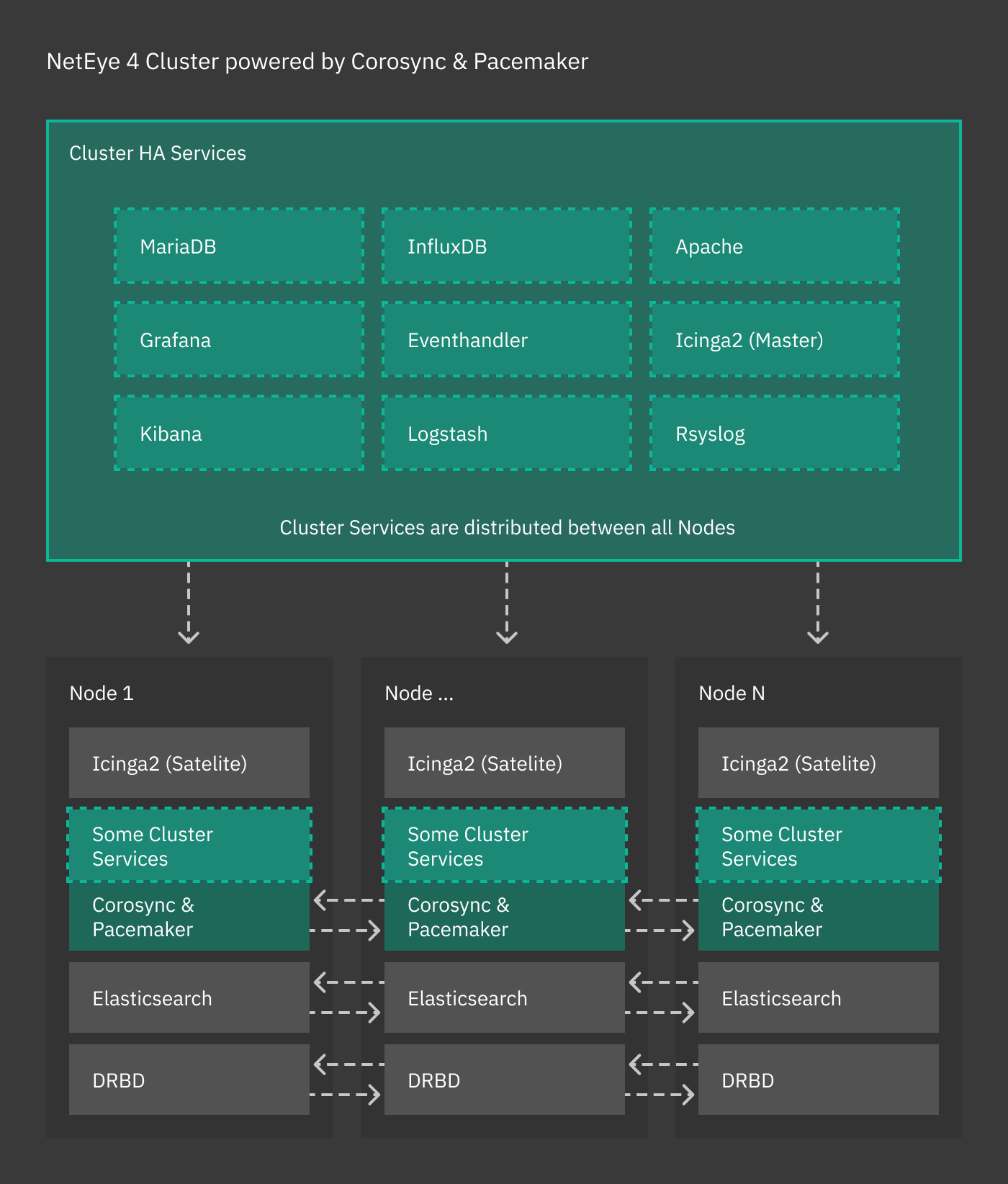
Fig. 3 The NetEye cluster architecture.¶
If you have not yet installed clustering services, please turn to the Cluster Installation page for setup instructions.
Type of Nodes¶
Within a NetEye cluster, different types of nodes can be setup. We distinguish between Operative and Single Purpose nodes, the latter being either Elastic-only or Voting-only nodes. They are
- Operative node
On an operative node runs any services offered by NetEye, like e.g., Tornado, Icinga 2, slmd, and so on. They can be seen as single nodes, connected by the clustering technologies mentioned above.
- Elastic-only node
Elastic-only nodes host only the DB component of the Elastic Stack, while FileBeat, Kibana, and other Elastic Stack components are still clusterised resources and run on operative nodes. Elastic-only nodes are used for either data storage or to add to the cluster more resources and processing abilities of elasticsearch data. In the latter case, the following are typical use cases:
Process log data in some way, for example with Machine Learning tools
Implement an hot-warm-cold architecture
Increase data retention, redundancy, or storage to archive old data
Note
An operative node may also run services of the Elastic Stack, including its DB component. In other words, it is not necessary to have a dedicated node for Elastic services.
- Voting-only node
Nodes of this type are a kind of silent nodes: They do not run any service and therefore require limited computational resources compared to the other nodes. They are needed only in case of a node failure to establish the quorum and avoid cluster disruption.
See also
Voting-only nodes and their use are described with great details in a NetEye blog post: https://www.neteye-blog.com/2020/03/neteye-voting-only-node/
The NetEye Active Node¶
During the update and upgrade operations, it is mandatory that one
of the operative nodes is always active during the procedures. The
nodes of a cluster are listed in the /etc/neteye-cluster file,
for example like the following.
{
"Hostname" : "my-neteye-cluster.example.com",
"Nodes" : [
{
"addr" : "192.168.1.1",
"hostname" : "my-neteye-01",
"hostname_ext" : "my-neteye-01.example.com",
"id" : 1
},
{
"addr" : "192.168.1.2",
"hostname" : "my-neteye-02",
"hostname_ext" : "my-neteye-02.example.com",
"id" : 2
},
{
"addr" : "192.168.1.3",
"hostname" : "my-neteye-03",
"hostname_ext" : "my-neteye-03.example.com",
"id" : 3
},
{
"addr" : "192.168.1.4",
"hostname" : "my-neteye-04",
"hostname_ext" : "my-neteye-04.example.com",
"id" : 4
}
],
"ElasticOnlyNodes": [
{
"addr" : "192.168.1.5",
"hostname" : "my-neteye-05",
"hostname_ext" : "my-neteye-05.example.com",
"id" : 5
}
],
"VotingOnlyNode" : {
"addr" : "192.168.1.6",
"hostname" : "my-neteye-06",
"hostname_ext" : "my-neteye-06.example.com",
"id" : 6
},
"InfluxDBOnlyNodes": [
{
"addr" : "192.168.1.7",
"hostname" : "my-neteye-07",
"hostname_ext" : "my-neteye-07.example.com"
}
]
}
The NetEye Active Node will always be the first node appearing in
the list of Nodes, in this case it is the node with FQDN
my-neteye-01.example.com and it is the one that must always be
active during the update/upgrade procedure.
Therefore, before running neteye update and
neteye upgrade, log in to my-neteye-01.example.com and
make sure that it is not in stand-by mode. To do so, first execute
the command to check the status of the cluster
cluster# pcs status
Then, if my-neteye-01.example.com is in standby, make it active
with command
cluster# pcs node unstandby my-neteye-01.example.com
See also
How nodes are managed by the NetEye update/upgrade commands is described with great details in a NetEye blog post: https://www.neteye-blog.com/2021/10/hosts-and-neteye-upgrade/
Clustering and Single Purpose Nodes¶
The following services use their own native clustering capabilities rather than Red Hat HA Clustering. NetEye will also take advantage of their inbuilt load balancing capabilities.
- Icinga 2 Cluster
An Icinga 2 cluster is composed by one master instance holding configuration files and by a variable number of satellites and agents.
See also
Icinga 2 clusters are described in great detail in the official Icinga documentation
- Elasticsearch
Each cluster node runs a local master-eligible Elasticsearch service, connected to all other nodes. Elasticsearch itself chooses which nodes can form a quorum (note that all NetEye cluster nodes are master eligible by default), and so manual quorum setup is no longer required.
See also
Elastic clusters and Elastic-only nodes are described with more details in the General Elasticsearch Cluster Information section.
Clustering Services¶
The combination of the following software is at the core of the NetEye’s clustering functionalities:
Corosync: Provides group communication between a set of nodes, application restart upon failure, and a quorum system.
Pacemaker: Provides cluster management, lock management, and fencing.
DRBD: Provides data redundancy by mirroring devices (hard drives, partitions, logical volumes, etc.) between hosts in real time.
“Local” NetEye services running simultaneously on each NetEye node
( i.e. not managed by Pacemaker and Corosync ), are managed by a
dedicated systemd target unit called
neteye-cluster-local.target. This reduced set of local services
is managed exactly alike the Single Node neteye target:
# systemctl list-dependencies neteye-cluster-local.target
neteye-cluster-local.target
● └─drbd.service
● └─elasticsearch.service
● └─icinga2.service
[...]
Cluster Management¶
There are several CLI commands to be used in the management and troubleshooting of clusters, most notably drbdmon, drbdadm, and pcs.
The first one, drbdmon is used to monitor the status of DRBD, i.e., to verify if the nodes of a cluster communicate flawlessly or if there is some ongoing issue, like e.g., a node or network failure, or a split brain.
The second command, drbdadm allows to carry out administrative tasks on DRBD.
Finally, the pcs command is used to manage resources on a pcs cluster only; its main purpose is to move services between the cluster nodes when required.
In particular, pcs status retrieves the current status of the nodes and services, while pcs node standby and pcs node unstandby put a node offline and back online, respectively.
More information and examples about these command can be found in section Cluster Management Commands.
Secure Intracluster Communication¶
Security between the nodes in a cluster is just as important as front-facing security. Because nodes in a cluster must trust each other completely to provide failover services and be efficient, the lack of an intracluster security mechanism means one compromised cluster node can read and modify data throughout the cluster.
NetEye uses certificates signed by a Certificate Authority to ensure that only trusted nodes can join the cluster, to encrypt data passing between nodes so that externals cannot tamper with your data, and allows for certificate revocation for the certificates of each component in each module.
Two examples of cluster-based modules are:
DRBD, which replicates block devices over the network
The ELK stack, which the NetEye 4 Log Management is based on.
Modules that Use Intracluster Security¶
The Log Manager modules use secure communication:
Module |
Enforcement Mechanism |
Component |
|---|---|---|
Log Manager |
X-Pack Security |
Elasticsearch |
Logstash |
||
Kibana |
NetEye Master¶
Active or passive monitoring processes are concentrated within the main NetEye instance - the NetEye Master. Based on the role distribution within the environment, the Master instance is responsible for:
holding configuration files
sending monitoring configurations to monitored objects previously created in the Director
receiving reports of events from various data sources, and matching those events with the predefined rules
executing actions based on the outcome of the performed analysis
configuring and initiating availability checks on a monitored infrastructure
The NetEye Master functionality for processing received data is granted by Icinga 2 monitoring server, Tornado Engine and Telegraf Consumers. The process of configuring monitoring tasks is controlled via the Director module.
Agents and Data Collecting¶
Retrieving data from the data sources is done by the local agents.
Collecting data for monitoring purposes is performed by means of Agents. Agent is a software that is to be installed on a node to monitor hosts and services. Apart from collecting data, agents are set to perform different tasks, e.g. process data or pass it to the Master, perform health ckecks.
In NetEye hierarchy agents can only have a parent node, i.e. either Master or Satellite. In case Satellites are not involved in the process of data communication, an Agent communicates directly with the Master instance.
While a Satellite can handle a set of hosts, different Agents can be installed on them. In their turn, Agents, can be grouped into tenants.
In order for an agent to operate successfully, make sure that versions of all involved instances are compatible. Namely, agent version should be the same as the version of a Satellite or Master it’s connected to.
Depending on the type of monitoring you would like to perform, i.e. NetEye module you would like to utilize, different agents can be installed on hosts: Icinga agent for Active monitoring purposes, Beats agent (SIEM), Telegraf agent, APM agent, AX Monitor agent, etc.
Icinga Agents
Icinga Agents communicate with the Master within their own Icinga infrastructure. Agents recieve configuration from the Master or a Satellite, and send collected data back to the Icinga instance on the Master. Configurations are generated and distributed to Icinga agents based on the zones.
Telegraf Agents
Local Telegraf Agents are to be configured manually as per which metrics are to be collected. Collected data is then passed to a Telegraf consumer on the Master for further processing. You can learn more on the Telegraf configuration at this page.
Elastic Agents
Elastic Agent is designed to collect and ship data from various sources to Elasticsearch. It is used to replace and consolidate multiple Beats and other agents previously used for data collection. Elastic Agents are pre-configured in the NetEye Master to serve as Fleet Servers: this allows you to easily install and manage Elastic Agents on you monitored hosts via the Fleet UI in Kibana.
GLPI Agents
GLPI Agents are to be installed and configured manually to collect assets and send them to the GLPI Server on the Master. They can be installed on any Windows/Linux machine and configured to send data directly to the Master or trough a NetEye Satellite as a Proxy.
To learn more about how to configure GLPI for Single- or Multitenant environments, please consult GLPI Configuration.
Alyvix Nodes
The Alyvix Node is to be installed and configured manually. NetEye communicates with the Alyvix Service via API calls through the HTTPS communication channels, while NATS serves as a communication channel to send the performance metrics from the Alyvix Nodes to the NetEye Master for service monitoring purposes. Alyvix Test Case execution reports are stored instead on the Alyvix Node.
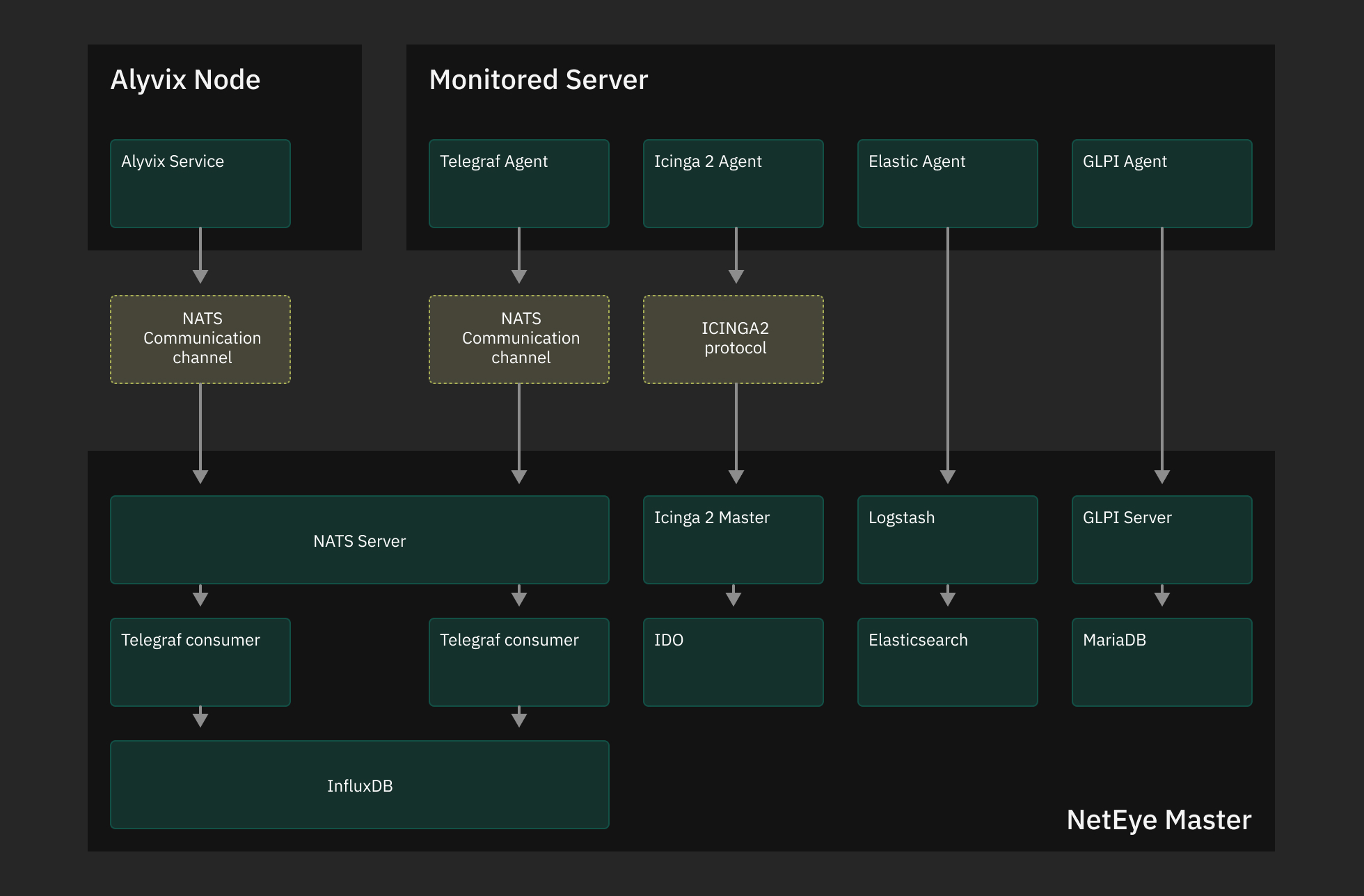
Fig. 4 Data communication from Agents to the Master.¶
Tornado Collectors
Data gathering for passive monitoring is performed by Tornado Collectors. Collected data flows down the Tornado pipeline, which, apart from the Collectors, contains Tornado Engine and Tornado Executors. The Engine and the Executors are deployed within the Master instance.
A Collector receives information from one or more unstructured sources (e.g. emails or log files), treated as External Events. Based on this a Collector converts External Events into structured Tornado-specific Events, and sends them to the Tornado Engine for further processing. Its main function is to match received events against preconfigured rules, and execute actions in case of a match.

Fig. 5 Outline of the Tornado Pipeline¶
See Passive Monitoring for more information on Tornado.
Master-Satellite Architecture¶
The Master can communicate with clients directly, or through a Satellite node. A Satellite forwards configurations from the Master to a client, collects data with agents and sends it back to the Master.
The Master can manage multiple tenants. Each Satellite connected to the Master is responsible for a set of hosts and/or services belonging to one tenant. There may be several Satellites functioning on a single tenant.
The monitoring configurations sent by the Master are individual for each Satellite and clients in its zone (where applicable). Communication between the Master and Satellites is secure and encrypted.
Communication through a Satellite¶
A Satellite is a NetEye instance which depends on a main NetEye installation, the Master, and is responsible for different tasks, including but not limited to,
execute Icinga 2 checks and forward results to the Master
collect logs and forward them to the Master
forward data through NATS
collect data through Tornado Collectors and forward them to the Master to be processed by Tornado
NetEye implements secure communication between Satellites and Master; each Satellite is responsible to handle a set of hosts. On hosts can be also installed different agents, software responsible to perform different tasks on the host itself and are connected to the Satellite.
See also
Icinga 2 Agents are presented in section Agent Nodes
A Satellite proves useful in two scenarios: to offload the Master and to implement multi tenancy.
As an example of the first scenario, consider an infrastructure that needs to monitor a large number of servers and devices, possibly located in multiple remote locations.
NetEye Satellites allow to reduce the load on Master and also the number of requests between Master and hosts. Indeed, all the checks are scheduled and executed by the Satellite and only their results are forwarded to the Master.
The second scenario sees NetEye Satellites operate in an isolated environment by implementing multi tenancy. For each tenant, multiple satellites can be specified that are responsible for monitoring and collecting logs. The Master receives data via Satellites or directly from the agents and identifies each tenant by means of the certificate installed on each Satellite.
The neteye satellites commands - provided by NetEye out of the box - can be very helpful to execute many operations to configure and manage the NetEye satellites.
See also
Please refer to Prerequisites to configure a Satellite; Update and upgrade procedures are explained in NetEye Satellites, Satellite Upgrade from 4.39 to 4.40 and Satellite Upgrade from 4.39 to 4.40, respectively.
Satellites communicate with other nodes using the NATS Server, the default message broker in NetEye. If you want to learn more about NATS you can refer to the official NATS documentation
Satellite Services¶
The services that need to run on the NetEye Satellite Nodes are managed by a dedicated systemd target
named neteye-satellite.target, which takes care of starting and stopping the services
of the Satellite when needed.
Various services are configured and activated out of the box on NetEye Satellites: among others, the Tornado Collectors and those provided by Icinga 2.
For the complete list of the services enabled on a NetEye Satellite, on the Satellite you can execute:
systemctl list-dependencies neteye-satellite.target
Data Gathering in NetEye Satellites¶
NetEye Satellites are used to collect data and send them to the Master, where they are stored and processed; for example they can later be used to set up dashboards.
NATS Communication¶
Communication between the Master and Satellites is performed by means of NATS service, with the exception of Icinga 2 communication.
NATS services are provided by one or more NATS server processes that are configured to interconnect with each other and provide a NATS service infrastructure throughout the NetEye Master and Satellites.
Data collected from a client is passed to a Master NATS Server through NATS Leaf Nodes. A Leaf Node authenticates and authorizes clients using local policy, allowing a relative Satellite to securely communicate with the Master.
NATS Leaf Node authenticates Satellites to the Master NATS Server, which can then assign the data coming from a Satellite to a single NetEye Tenant, based on the configuration.
It is the Satellite that initiates communication with the Master, so it’s important to make sure the requirements for a NATS Leaf Node are met for the data transfer to be carried out successfully.
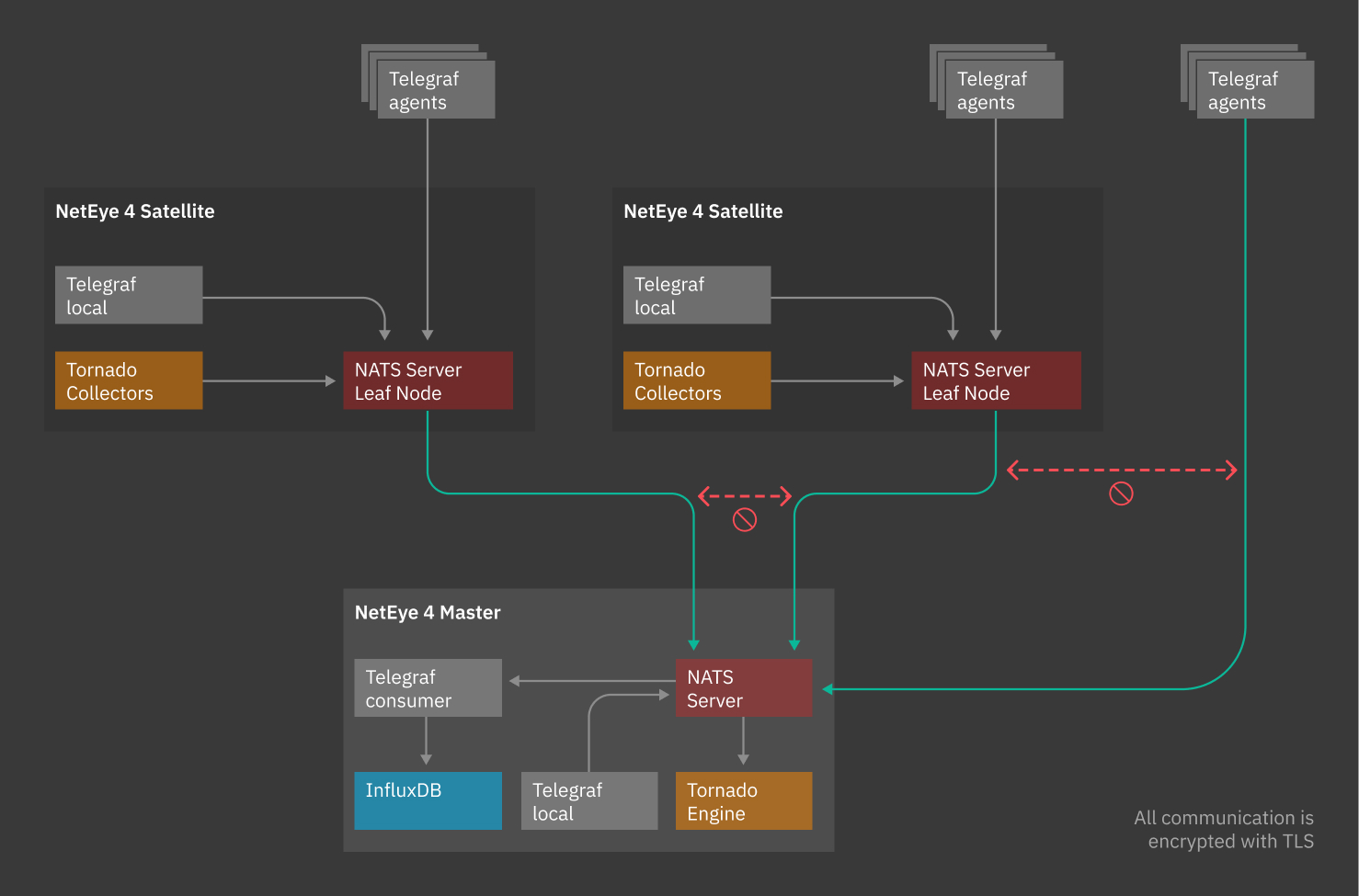
Fig. 6 Communication through NATS¶
Multi Tenancy and NATS Leaf¶
One interesting functionality provided by NATS Server is the support for a secure, TLS-based, multi tenancy, that can be secured using multiple accounts. As stated in Multi Tenancy using Accounts NATS Server supports creating self-contained, isolated communications from multiple clients to a single server, that will then independently process all data streams. This ability is exploited by NetEye, where the single server runs on the NetEye Master and the clients are the NetEye Satellites.
On each Satellite a NATS Server, which runs as NATS Leaf Node, collects data from the hosts that the Satellite is monitoring and forwards them to the NetEye Master’s NATS Server. Thanks to the configuration done by NetEye, when NATS Leaf Nodes authenticate to the Master’s NATS Server, they are automatically associated with the respective NATS Account (which represents a Tenant) so that each Tenant’s data flow is isolated.
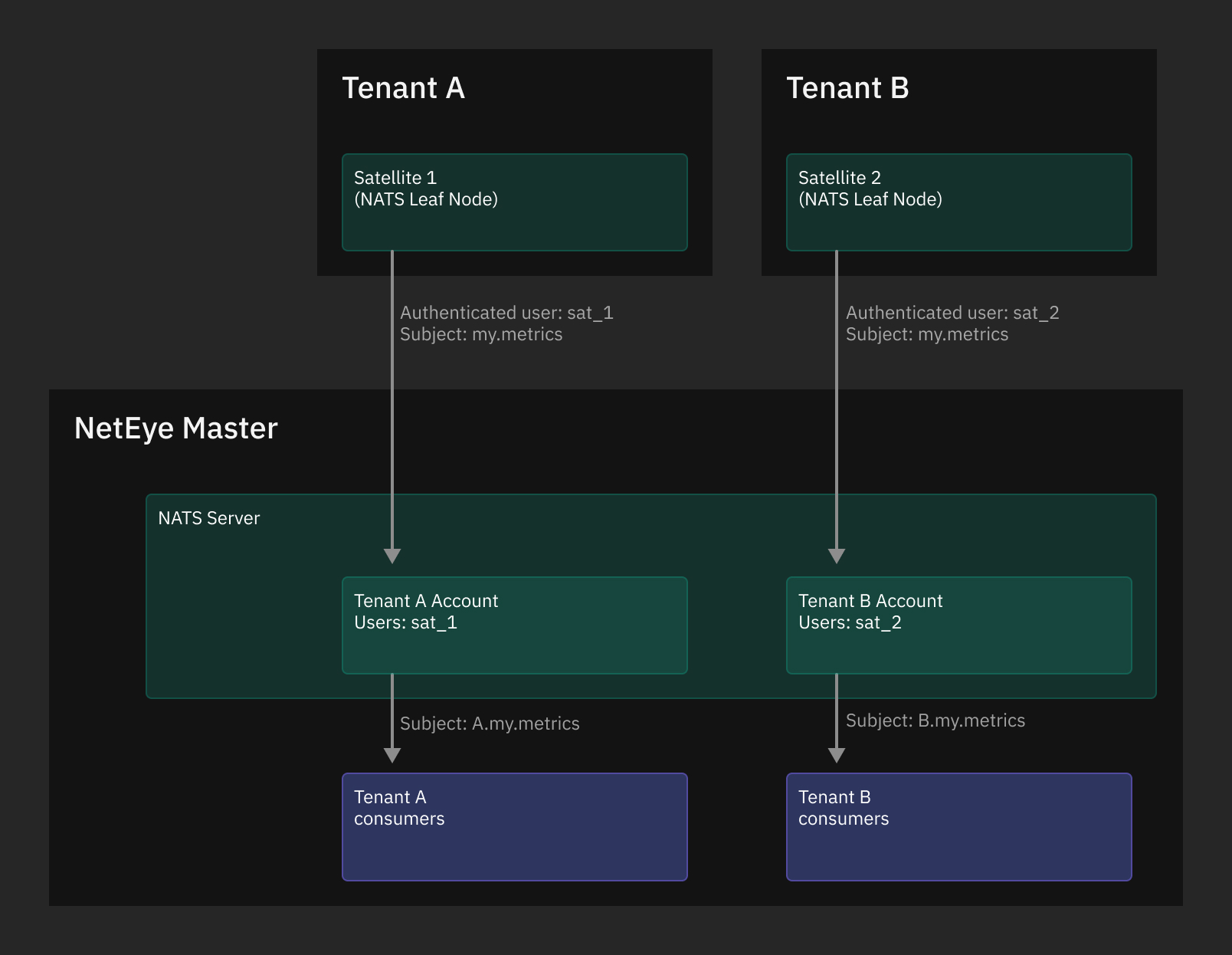
Fig. 7 NATS Server in a multi-tenant environment.¶
On the Master, one Telegraf local consumer instance for each Tenant is spawned: the service
is called telegraf-local@neteye_consumer_influxdb_<tenant_name> and will consume
only contents from subject <tenant_name>.telegraf.metrics.
If you are in a cluster environment, an instance of Telegraf local consumer is
started on each node of the cluster, to exploit the NATS built-in load balancing feature
called distributed queue. For more information about this feature, see the official
NATS documentation.
Data are stored in InfluxDB: data from each Satellite are written in a specific database,
that belongs to the Tenant, called <tenant_name> in order to allow data isolation
in a multi-tenant environment.
To learn more about Telegraf configuration please check Telegraf Configuration section
Multi Tenancy configuration explained¶
The procedure to configure a NetEye Satellite automatically configures NATS Accounts on the Master and NATS Leaf Node on the Satellites. In this section we will give an insight into the most relevant configurations performed by the procedure.
The automatic procedure configures the following:
NATS Server
On the NATS Server of the NetEye Master, for each NetEye Tenant a dedicated Account is created. For each satellite a user is created and associated to its Tenant account. This is done with the purpose to isolate the traffic of each Tenant. This way, the NATS subscribers on the NetEye Master will receive the messages coming from the Satellites and from the Master itself. NATS Subscribers on a NetEye Satellite will not be able to access the messages coming from the other NetEye Tenants.
The stream subjects coming from the NetEye Satellites are prefixed with the Tenant unique identifier defined during the NetEye Satellite configuration. This is done in order to let subscribers securely pinpoint the origin of the messages, by solely relying on the NATS subject. So, for example, if the NATS Leaf Node of NetEye Satellite acmesatellite belonging to the tenantA publishes a message on subject mysubject, NATS subscribers on the NetEye Master will need to subscribe to the subject tenantA.mysubject in order to receive the message.
NATS Satellite:
A server certificate for the Satellite NATS Leaf Node is generated with the Root CA of the NetEye Satellite. This must be trusted by the clients that need to connect to the NetEye Satellite NATS Leaf Node.
A client certificate is generated with the Root CA of the NetEye Master. This is used by the NATS Leaf Nodes to authenticate to the NetEye Master NATS Server.
The NATS Leaf Node is configured to talk to the NATS Server of the NetEye Master, using the FQDN defined during the NetEye Satellite configuration and the port 7422.
Underlying Operating System¶
Since release of NetEye 4.23, we build our product on top of Red Hat Enterprise Linux 8 (RHEL 8). This allows us to benefit from the feature an utilities Red Hat provide with RHEL and pass that onto our clients.
RHEL 8 Life Cycle¶
The RHEL 8 Life Cycle covers at least 10 Years. In the first five years of its lifetime, RHEL 8 gets full support from Red Hat. This means all packages will receive security updates and bug fixes, as well as selected software enhancements at the discretion of Red Hat. The focus for minor releases during this phase lays on resolving defects of medium or higher priority. Full Support is projected to end on May 31, 2024.
After that, RHEL 8 will transition into the Maintenance Support Phase. In this phase the packages will still get high priority security and bug fixes, however no minor version upgrades or enhancements. The Maintenance Support Phase is projected to end on May 31, 2029.
The last phase is the Extended Life Phase. In this phase, Red Hat provides no longer updated installation images. The technical support is limited to the pre-existing installations and no updates will be rolled out. To keep support and updates into this last phase, there exist Support Add-ons for the subscription, to guarantee extra support even after the end of the Maintenance Support Phase. The Extended Life Phase is projected to end on May 31, 2031.
See also
For more information on RHEL 8 Life Cycle visit official Red Hat Customer Portal
Red Hat Insights Integration¶
NetEye and the Red Hat subscription are also integrated with Red Hat Insights, which allows us a quick overview of all systems registered under our licenses. It also lists some NetEye specific data for each server, like the role, server and deployment type, serial number, NetEye version, installed NetEye dnf groups and more.
Registration is done during neteye install but first you need to run the following command
in order to generate the correct tags that will be associated with the machine.
neteye# neteye node tags set
See also
For more information see the section on the neteye node tags command.
Security Guarantees¶
Red Hat guarantees, that to its knowledge, the Software does not, at the time of delivery to you, include malicious mechanisms or code for the purpose of damaging or corrupting the Software; and the Services will comply in all material respects with laws applicable to Red Hat as the provider of the Services.
The Red Hat Open Source Assurance program furthermore protects the clients from the effects of an intellectual property infringement claim on any Red Hat products. This may include: (i) replacing the infringing portion of the software, (ii) modifying the software so that its use becomes non-infringing, or (iii) obtaining the rights necessary for a customer to continue use of the software.
See also
These guarantees are stated in the Red Hat Enterprise Agreement https://www.redhat.com/en/about/agreements
Security Fixes¶
Red Hat will provide backports of security fixes until the EOL of the package. However the package name does not always follow the semantic versioning conventions of the upstream source. Red Hat will only increase the revision number of their packages when backporting bug fixes. That may lead to some confusion if the upstream release was patched in a newer version, than the one provided by Red Hat. If external auditing tools rely solely on the version of the package, this may also lead to false positives.
Red Hat and CVEs¶
Red Hat adds the CVE names to all Red Hat Security Advisories for easier cross-referencing since 2001. This makes it easy to check if a system is affected by a certain CVEs. Red Hat provides the Red Hat CVE Database where one can look up releases for a certain CVE. RHEL also provides the oscap command-line utility which scans the system for known vulnerabilities and policy violations. CVEs for which RHEL issues a Security Advisor can be viewed in the Vulnerability service.
See also
Red Hats CVE Q&A https://access.redhat.com/articles/2123171