El Proxy Security¶
The process of log management provided within NetEye grants data integrity and inalterability due to the feature implementation methods, in order to comply with standard NetEye policies.
El Proxy Security section should serve as a proof of El Proxy being a reliable tool for signing your logs and safely sending them to Elasticsearch. The implementation of El Proxy encounters risks mitigations, so that the data corruption is preventable, or on the other hand, traceable.
The main aspects of security within mentioned software are covered in:
Secured methods of communication and authentication
Log signature flow, explaining the logic of how El Poxy actually works
Error handling strategies El Proxy uses to recover after failures
Healthchecks that are run to make sure log collecting process wasn’t error-prone
Additionally, this section highlights some details of the configuration and can be used to modify the setup if required.
Secure Communication¶
When installed on NetEye, the El Proxy automatically starts in secure mode using TLS. Additionally, authentication with Elasticsearch is protected by certificates.
TLS Configuration¶
Advanced users should be able to check the location of the configuration files or modify the setup.
The El Proxy server can start in HTTP or HTTPS mode; this is
configured in the config web_server.tls section.
The available modes are:
None: The El Proxy server starts with TLS disabled. Example:
[web_server.tls] type = "None"
PemCertificatePath: The El Proxy server starts with TLS enabled using the PEM certificates read from the local file system. When this method is used, the following information must be provided:
certificate_path: path to the server public certificate
private_key_path: path to the server private key
Example:
[web_server.tls] type = "PemCertificatePath" certificate_path = "/path/to/certs/ebp_server.crt.pem" private_key_path = "/path/to/certs/private/ebp_server.key.pem"
Authentication to Elasticsearch¶
When the Elasticsearch client is created, the authentication method to be used to connect to Elasticsearch needs to be specified. The authentication method defined in the configuration file is only used for the serve command.
The available authentication methods are:
None: the client connects to Elasticsearch without authentication. Example:
[elasticsearch.auth] type = "None"
BasicAuth: the client authenticates to Elasticsearch with username and password. When this method is used, the following information must be provided:
username: name of the Elasticsearch user
password: the password for the Elasticsearch user
[elasticsearch.auth] type = "BasicAuth" username = "myuser" password = "mypassword"
PemCertificatePath: the client connects to Elasticsearch using the PEM certificates read from the local file system. When this method is used, the following information must be provided:
certificate_path: path to the public certificate accepted by Elasticsearch
private_key_path: path to the corresponding private key
Example:
[elasticsearch.auth] type = "PemCertificatePath" certificate_path = "/path/to/certs/ebp.crt.pem" private_key_path = "/path/to/certs/private/ebp.key.pem"
Log Signature Flow¶
Generation of Signature Keys¶
El Proxy achieves secure logging by authentically encrypting each log record with an individual cryptographic key, which protects the integrity of the whole log archive by a cryptographic authentication code. The key is unique and is used for signing only once.
Each key is bound to a specific customer, module, retention policy and a tag. A unique combination of values of all mentioned properties serves to define a single blockchain the incoming log will be added to.
An encryption key for the initial log in a blockchain is generated upon the event
of receiving the log from Logstash to be signed. The key file is saved
on the filesystem in the {data_dir} folder with the following naming convention:
{data_dir}/{customer}/{module}-{customer}-{retention_policy}-{blockchain_tag}_key.json
The key file is expected to contain:
{
"key": "initial_key",
"iteration": 0
}
where:
keyis the initial encryption key the initial log is signed withiterationis the iteration number for which the signature key is valid.
As the initial log is signed with the initial key, a new pair key/iteration is generated based on the latest key used for signature, where
keyequals to the SHA256 hash of the previous keyiterationequals to the previous iteration incremented by one
For example, if the key at iteration 0 is:
{
"key": "abcdefghilmno",
"iteration": 0
}
the next key will be:
{
"key": "d1bf0c925ec44e073f18df0d70857be56578f43f6c150f119e931e85a3ae5cb4",
"iteration": 1
}
After the initial log is signed, a copy of the key file is created in
the {data_backup_dir} folder with the following naming convention:
{data_backup_dir}/{customer}/{module}-{customer}-{retention_policy}-{blockchain_tag}_key.json
As soon as a new key file appears in the {data_backup_dir} folder,
the Icinga2 service logmanager-blockchain-keys-neteyelocal will enter
in CRITICAL state, indicating that a new key has been generated in the system.
The new key must be moved in a safe place such as a password manager or a storage
with restricted access.
This mechanism creates a blockchain of keys that cannot be altered without breaking the validity of the entire chain.
Every time a set of logs is successfully sent to Elasticsearch, a corresponding key file is updated with a new value. This way each reference to the keys that were used for signature is removed from the system, making it impossible to recover and reuse old keys.
However, in case of unmanageable Elasticsearch errors, the El Proxy will reply with an error message to Logstash and will reuse the keys of the failed call for the next incoming logs.
Note
To be valid, the iteration values of signed logs in
Elasticsearch should be incremental with no missing or duplicated
values.
When the first log is received after its startup, the El Proxy calls
Elasticsearch to query for the last indexed log iteration value to
determine the correct iteration number for the next log. If the
last log iteration value returned from Elasticsearch is greater
than the value stored in the key file, the El Proxy will fail to
process the log.
Usage of Signature Keys¶
For each incoming log, the El Proxy retrieves the first available encryption key, as described in the previous section, and then uses it to calculate the HMAC-SHA256 hash of the log.
The calculation of the HMAC hash takes into account:
the log itself as received from Logstash
the iteration number
the timestamp
the hash of the previous log
At this point, the signed log is a simple JSON object composed by the following fields:
All fields of the original log : all fields from the original log message
ES_BLOCKCHAIN: an object containing all the El Proxy’s calculated values. They are:
fields: fields of the original log used by the signature process
hash: the hmac hash calculate as described before
previous_hash: the hmac hash of the previous log message
iteration: the iteration number of the signature key
timestamp_ms: the signature epoch timestamp in milliseconds
For example, given this key:
{
"key": "d1bf0c925ec44e073f18df0d70857be56578f43f6c150f119e931e85a3ae5cb4",
"iteration": 11
}
when this log is received:
{
"value": "A log message",
"origin": "linux-apache2",
"EBP_METADATA": {
"agent": {
"type": "auditbeat",
"version": "7.10.1"
},
"customer": "neteye",
"retention": "6_months",
"blockchain_tag": "0",
"event": {
"module": "elproxysigned"
}
}
}
then this signed log will be generated:
{
"value": "A log message",
"origin": "linux-apache2",
"EBP_METADATA": {
"agent": {
"type": "auditbeat",
"version": "7.10.1"
},
"customer": "neteye",
"retention": "6_months",
"blockchain_tag": "0",
"event": {
"module": "elproxysigned"
}
},
"ES_BLOCKCHAIN": {
"fields": {
"value": "A log message",
"origin": "linux-apache2"
},
"hash": "HASH_OF_THE_CURRENT_LOG",
"previous_hash": "HASH_OF_THE_PREVIOUS_LOG",
"iteration": 11,
"timestamp_ms": 123456789
}
}
The diagram shown in Fig. 206 offers a detailed view on how El Proxy uses the Signature Keys to sign a batch of Logs.
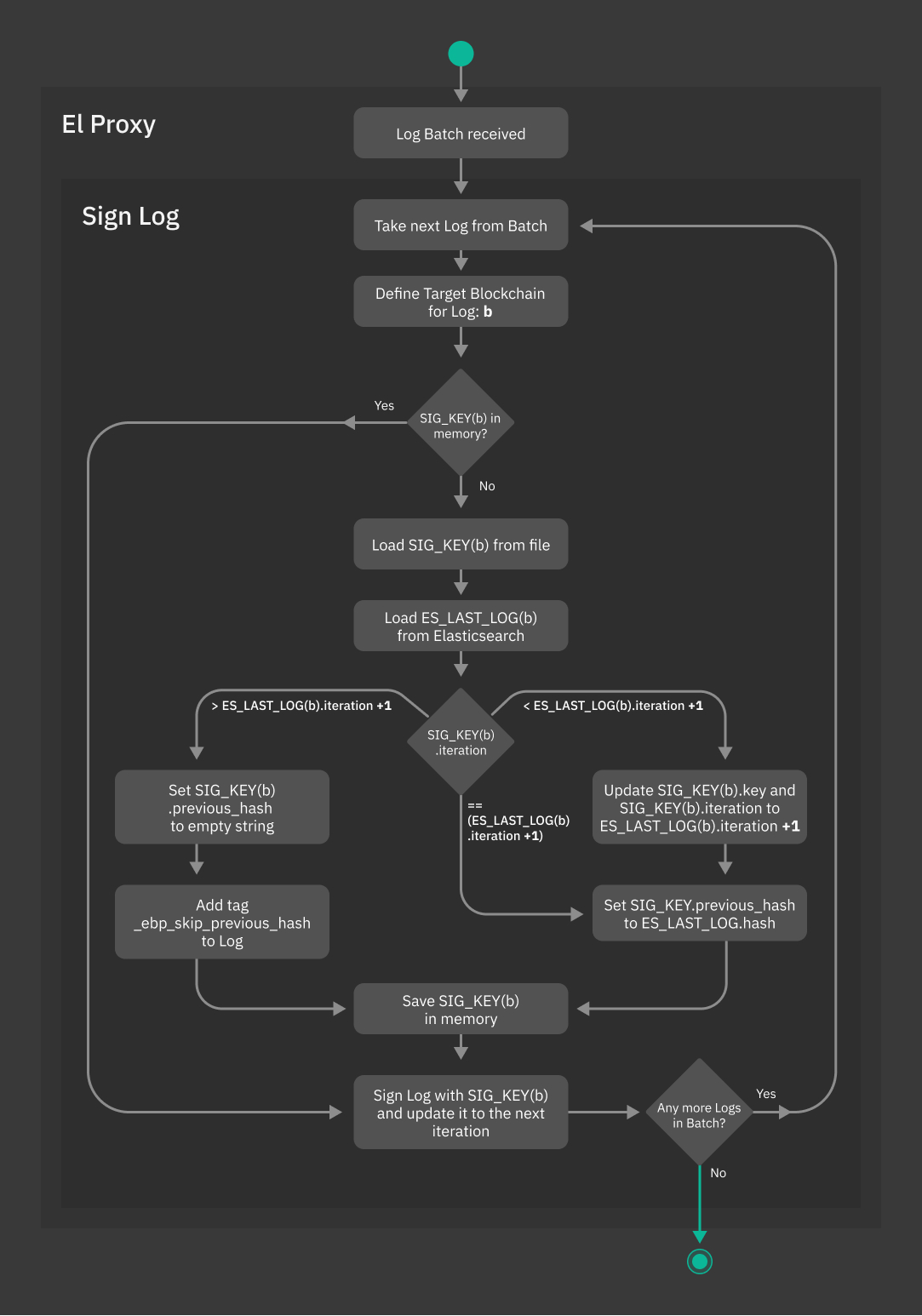
Fig. 206 El Proxy Log Signing flowchart¶
Below you can find the meaning of the variables used in the flowchart.
- SIG_KEY(b)
The key used to sign the logs of a given Blockchain b.
- ES_LAST_LOG(b)
The log with greatest iteration saved in Elasticsearch for the Blockchain b.
How the index name is determined¶
The name of the Elasticsearch index for the signed logs is determined by the content of
the EBP_METADATA field of the incoming Log.
The index name has the following structure:
{EBP_METADATA.agent.type}-{EBP_METADATA.agent.version}-{EBP_METADATA.event.module}-{EBP_METADATA.customer}-{EBP_METADATA.retention}-{EBP_METADATA.blockchain_tag}-YYYY.MM.DD
The following rules and constraints are valid:
All of these fields are mandatory:
EBP_METADATA.agent.typeEBP_METADATA.customerEBP_METADATA.retentionEBP_METADATA.blockchain_tag
The
YYYY.MM.DDpart of the index name is based on the epoch timestamp of the signatureIf the
{EBP_METADATA.event.module}is not present, El Proxy will use by defaultelproxysigned
For example, given this log is received on 23 March, 2021:
{
"value": "A log message",
"origin": "linux-apache2",
"EBP_METADATA": {
"agent": {
"type": "auditbeat",
"version": "7.10.1"
},
"customer": "neteye",
"retention": "6_months",
"blockchain_tag": "0",
"event": {
"module": "elproxysigned"
}
}
}
Then the inferred index name is: auditbeat-7.10.1-elproxysigned-neteye-6_months-0-2021.03.23
As a consequence of the default values and of the default Logstash configuration,
most of the indexes created by El Proxy will have elproxysigned in the name.
Consequently, special care should be applied when manipulating those indexes and documents;
in particular, the user must not delete or rename *-elproxysigned-* indices manually nor alter
the content of ES_BLOCKCHAIN or EBP_METADATA fields as any change could lead to a broken
blockchain.
How Elasticsearch Ingest Pipeline are defined for each log¶
A common use case is that logs going through El Proxy need to be enriched by some Elasticsearch Ingest Pipeline when they are indexed in Elasticsearch.
El Proxy supports this use case and allows its callers to specify, for each log, the ID
of Ingest Pipeline that needs to enrich the log. The ID of the Ingest Pipeline is
defined by the field EBP_METADATA.pipeline of the incoming log.
If EBP_METADATA.pipeline is left empty, the log will not be preprocessed by any
specific Ingest Pipeline.
Error Handling¶
El Proxy implements two different recovery strategies in case of errors. The first one is a simple retry strategy used in case of unrecoverable communication errors with Elasticsearch; the second one, instead, is used in case Elasticsearch has issues with processing some of the sent logs and aims at addressing a widely known issue named backpressure.
Figure Fig. 207 shows how El Proxy integrates the two aforementioned strategies, which will be thoroughly explained in the next paragraphs.
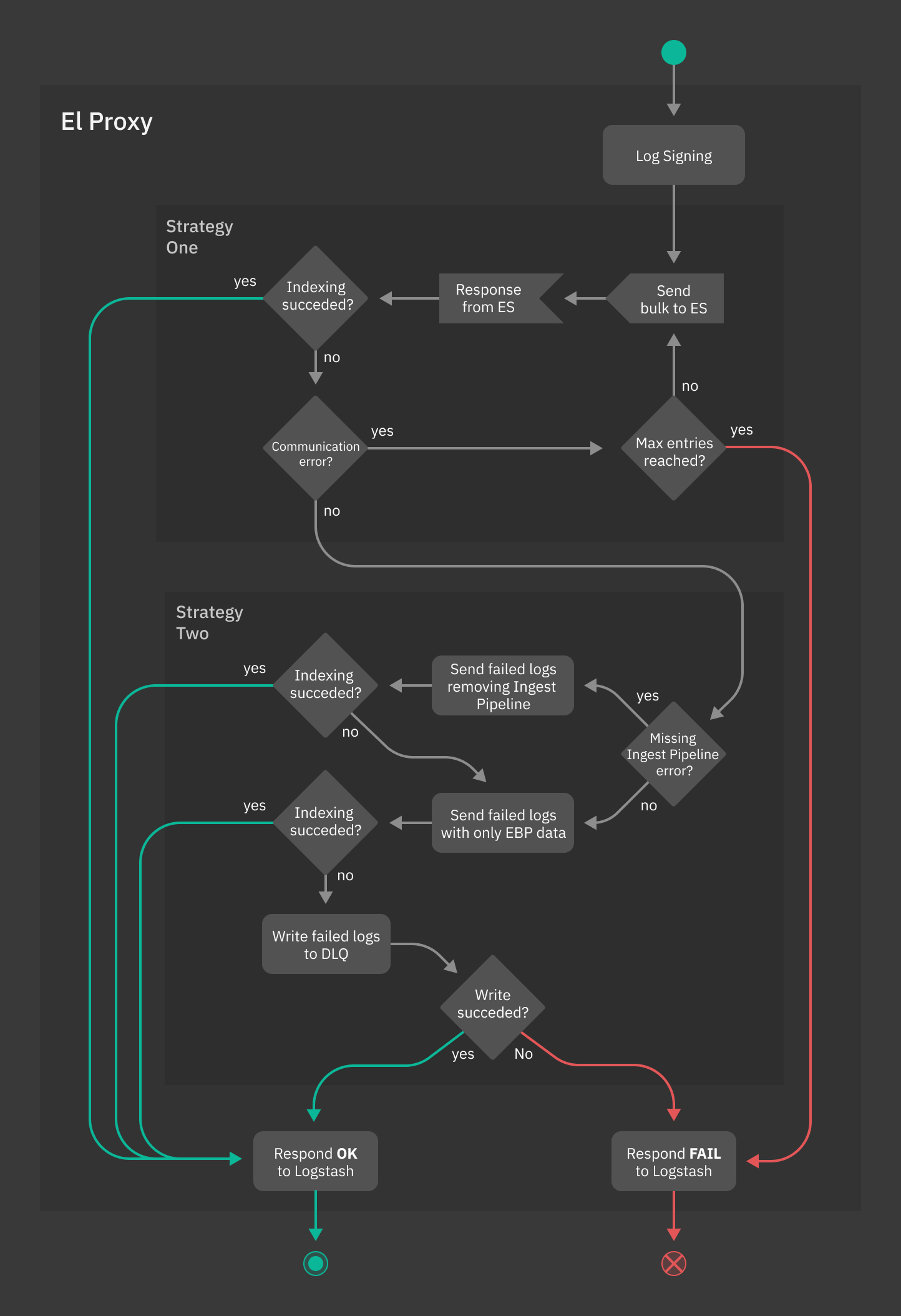
Fig. 207 Error Handling in El Proxy¶
Strategy One: Bulk retry¶
El Proxy implements an optional retry strategy to handle communication errors with Elasticsearch; when enabled (see the Configuration section), whenever a generic error is returned by Elasticsearch, El Proxy will retry for a fixed amount of times to resubmit the same signed_logs to Elasticsearch.
This strategy permits to deal, for example, with temporary networking issues without forcing Logstash to resubmit the logs for a new from-scratch processing.
Nevertheless, while this can be useful in dealing with a large set of use cases, it should also be used very carefully. In fact, due to the completely sequential nature of the blockchain processing, a too high number of retries could lead to an ever growing queue of logs waiting to be processed while El Proxy is busy with processing over and over again the same failed logs.
In conclusion, whether it is better to let El Proxy fail fast or retry more times is a decision that needs a careful, case-by-case analysis.
Strategy Two: Single Log Reprocessing and Dead Letter Queue¶
In some cases, Elasticsearch can correctly process the log bulk request but it can fail to index some of the contained logs. In this situation, El Proxy reprocesses only those failed logs and follows a procedure aimed at ensuring that each signed log will be indexed in Elasticsearch.
The procedure is the following:
If the log indexing error is caused by the fact that the Elasticsearch Ingest Pipeline specified for the log does not exist in Elasticsearch, then:
El Proxy tries to index again the log without specifying any Ingest Pipeline. When doing this, El Proxy will also add the tag
_ebp_remove_pipelineto the Elasticsearch document, so that once the log is indexed, it will be visible that the Ingest Pipeline was bypassed during the document indexing.If the indexing fails again, El Proxy proceeds with step 2 of this procedure.
El Proxy removes from the failed log all the fields not required by the signature process and sends the modified document to Elasticsearch. Note that also all the document tags (including the
_ebp_remove_pipelinetag) will be removed from the document.This strategy is based on the assumption that the indexing of the specific log fails due to incompatible operations requested by a pipeline. For example, a pipeline could attempt to lowercase a non-string field causing the failure. Consequently, resubmitting the log without the problematic fields could lead to a successful indexing.
If after following this procedure some logs are still not indexed in Elasticsearch, then El Proxy will dump the failed logs to a Dead Letter Queue on the filesystem and it will send an ok response to Logstash. Usually, when this happens, the blockchain will be in an incoherent state caused by holes in the numeric progression iteration. The administrator is in charge of investigating the issue and, if possible, recover the non-indexed logs with the dlq recover command or manually acknowledge the problem.
As mentioned before, the Dead Letter Queue is saved on the filesystem inside the
{dlq_dir} folder as set in the configuration file.
The Dead Letter Queue consists of a set of text files in Newline delimited JSON format
with each row in a file representing a failed log.
These files are grouped by customer and index name following the naming convention:
{dlq_dir}/{customer}/{index_name}.ndjson
where {index_name} is the name of the Elasticsearch index where the failed logs
were supposed to be written.
If the dlq recover command is used to recover the logs, the tag _ebp_dlq_recovered
is added to each log at the moment of indexing in Elasticsearch. The successfully
recovered logs are moved inside the {dlq_recovered} folder as
set in the configuration file. The logs that failed to be recovered remain
unchanged in the {dlq_dir} folder.
If the administrator wants to move the logs from the {dlq_dir} manually,
the convention is to move them inside a folder called {archive_dlq}.
The parent folder of each NDJSON file should
not be changed. So the naming convention for a manually moved file should be:
{dlq_recovered}/{customer}/{index_name}.ndjson
Each entry in the Dead Letter Queue file contains the original log whose indexation failed and, if present, the Elasticsearch error that caused the failure. For example:
{
"document": {
"value": "A log message",
"origin": "linux-apache2",
"EBP_METADATA": {
"agent": {
"type": "auditbeat",
"version": "7.10.1"
},
"customer": "neteye",
"retention": "6_months",
"blockchain_tag": "0",
"event": {
"module": "elproxysigned"
}
},
"ES_BLOCKCHAIN": {
"fields": {
"value": "A log message",
"origin": "linux-apache2"
},
"hash": "HASH_OF_THE_CURRENT_LOG",
"previous_hash": "HASH_OF_THE_PREVIOUS_LOG",
"iteration": 11,
"timestamp_ms": 123456789
}
},
"el_error": {
"reason": "field [string_field] of type [java.lang.Integer] cannot be cast to [java.lang.String]",
"type": "illegal_argument_exception"
}
}
Health Checks¶
To make sure that the blockchain is sound and no errors occurred during the collection of the logs, NetEye defines different Health Checks to alert the users of any irregularities that may occur.
logmanager-blockchain-creation-status: Makes sure that all logs are written correctly into the blockchain.
If this Health Check is CRITICAL, it means that some logs could not be written successfully to Elasticsearch. The logs in question are then written to the Dead Letter Queue, where you can also find the reason for which they could not be indexed in Elasticsearch.
To resolve this issue visit section Handling Logs in Dead Letter Queue
logmanager-blockchain-keys: Verifies that no backup of the Signature Key is present on the NetEye installation, to prevent any tampering on the blockchains from a compromised system.
Background and solution for this issue can be found in Log Signature Flow.
logmanager-blockchain-missing-elasticsearch-pipeline: Checks if any Elasticsearch ingest pipeline used to enrich logs is missing.
If a log was sent through Logstash with a non-existing pipeline, Elasticsearch will refuse to persist the log and return with an error. As seen in Error Handling, the Health Check then periodically queries Elasticsearch for logs with a corresponding tag and if found, set the status to CRITICAL.
To resolve this, remove the tags from the document in Elasticsearch.
Blockchain Verification¶
In order to ensure the underlying blockchain was not altered or corrupted, you can use verify command provided by El Proxy. Prior to running the command, you need to perform the verification setup.
The command retrieves signature data of each log stored in the Elasticsearch blockchain, recalculates the hash of each log and compares it with the one stored in the signature, reporting a CorruptionId for all non-matching logs of the blockchain. The CorruptionId can then also be used with the acknowledge command, as explained in section Acknowledging Corruptions of a Blockchain.
By default, the command verifies always two batches in parallel, however the argument
--concurrent-batches allows the user to increase the amount of parallel workers.
The flowchart depicted in figure Fig. 208 provides a detailed view of the operations performed during the verification process and the reporting of discovered corruptions.
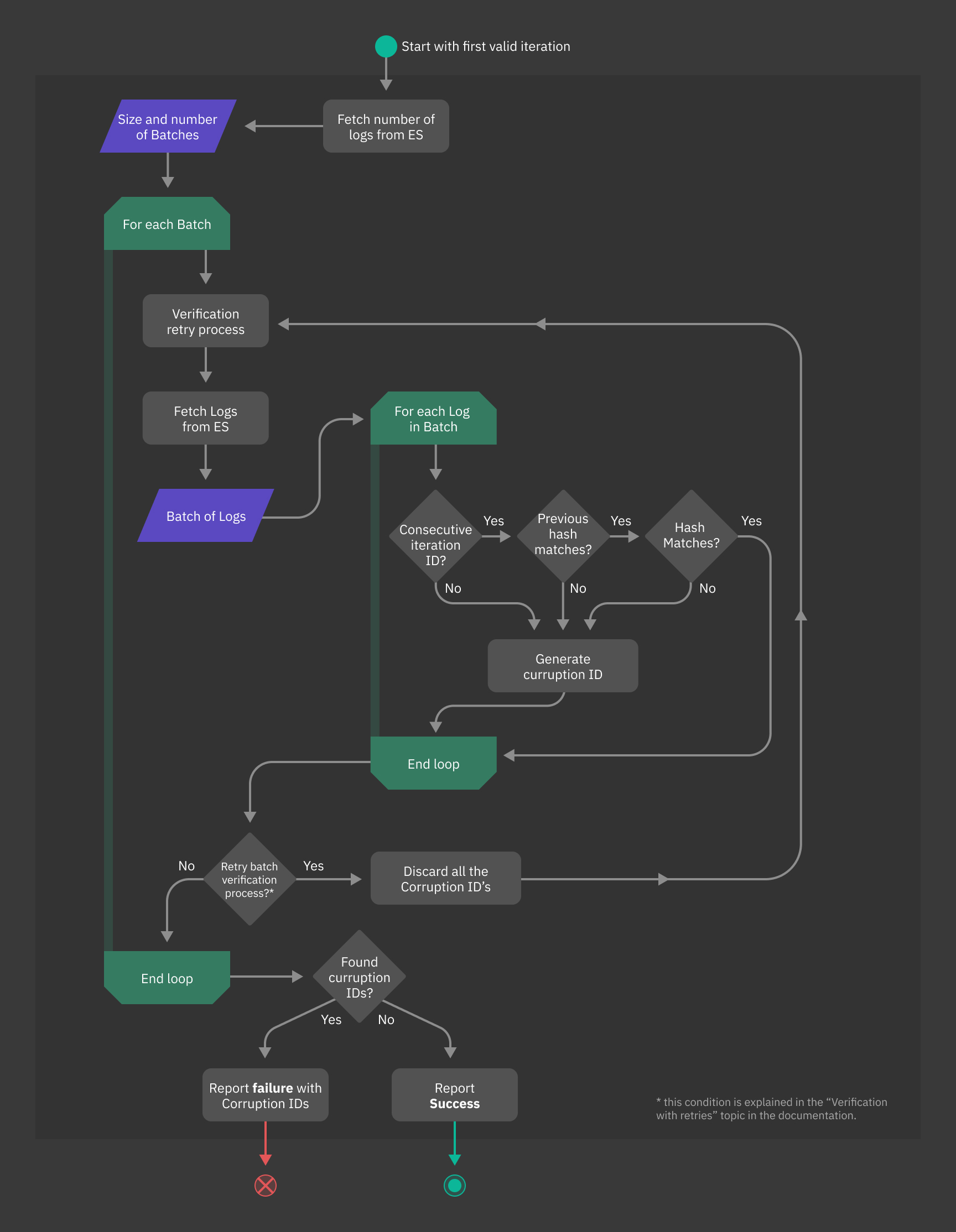
Fig. 208 El Proxy verification process Overview¶
For more information on the verify command and its parameters, please consult the associated El Proxy commands section.
Verification and Retention Policies
The blockchain stored in Elasticsearch is subject to a specific retention policy which defines how long the logs will be kept. When the logs reach their maximum age, Elasticsearch deletes them. If the logs inside the blockchain get deleted as an effect of the retention policy, it is impossible to verify the blockchain from start to end. For this reason, El Proxy must consider the retention policy and thus start verifying the blockchain from the first present log.
El Proxy uses a so-called Blockchain State History (BSH) file to retrieve the first present log inside the blockchain. This file is updated on every successful verification and contains one entry for each day that specifies the first and last iteration of the indexed logs for that day.
When the verify command is executed, El Proxy fetches the BSH file searching for the entry corresponding to the first day that still contains all the logs at the moment of the verification. If the entry is present, El Proxy can retrieve the first iteration for that day and start the verification from the iteration specified in the entry. If the entry is not present or El Proxy cannot get the first iteration from the BSH, then El Proxy directly queries Elasticsearch to retrieve the first present log.
Note that although querying Elasticsearch is an option, the only way for El Proxy to verify the blockchain’s integrity is to retrieve the first iteration from the BSH. For this reason, if the first log is retrieved by querying Elasticsearch, the verify command will throw a warning after the successful verification. For more information about warnings and errors that could appear during the verification, please consult associated section.
First Iteration Retrieval¶
During the verification process, one of the first steps performed by El Proxy is the retrieval of the first expected iteration. This aspect is particularly important when considering the retention policies, since the first expected iteration needs to be calculated based on the logs that we still expect to find in Elasticsearch. The following diagram outlines the first steps of the verification process which involve the retrieval of the first iteration and the various errors or warnings raised.
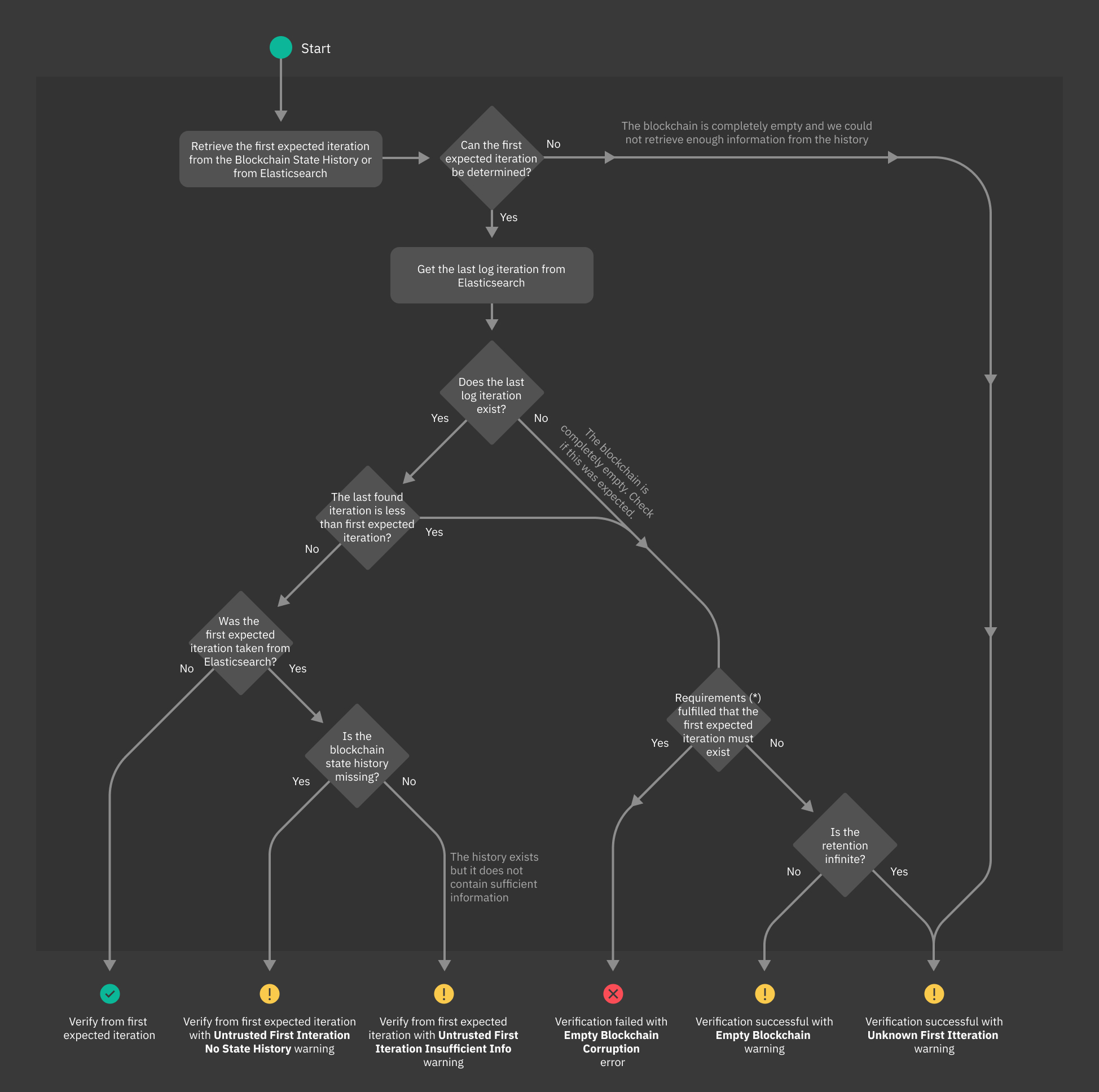
Fig. 209 El Proxy verification process - First iteration retrieval.¶
(*) for more information please refer to the following Must Exists vs May Exist section
Verification with Retries
The elasticsearch-indexing-delay parameter of the verify command can help when the Blockchain subject to verification contains recently created logs. The reason is that Elasticsearch might take some time to index a document; therefore, El Proxy could be trying to verify a batch in which some logs are missing. In order to avoid the erroneous failure of the verification, if El Proxy detects that some logs could be missing because of an indexing delay of Elasticsearch, it repeats the whole batch verification. The parameter elasticsearch-indexing-delay defines the maximum allowed time in seconds for Elasticsearch to index a document. If Elasticsearch takes more than elasticsearch-indexing-delay seconds to index a log, the verification will fail (see El Proxy Configuration). If we name timestamp_next_log the timestamp of the next present log and timestamp_verification the timestamp of the log verification, El Proxy considers a log as missing due to Elasticsearch indexing delay whenever timestamp_next_log > timestamp_verification - elasticsearch-indexing-delay. It is worth noticing that El Proxy will always retry the batch verification for a finite amount of time, corresponding to elasticsearch-indexing-delay seconds in the worst case.
Acknowledging Corruptions of a Blockchain¶
The correct state of a blockchain can be checked by executing the verify command, which provides, at the end of its execution, a report about the correctness of the inspected subject. If everything is fine, the verification process will complete successfully, otherwise, the execution report will contain a list of all errors encountered. For example:
--------------------------------------------------------
--------------------------------------------------------
Verify command execution completed.
Blockchain verification process completed with 2 errors.
--------------------------------------------------------
Errors detail:
--------------------------------------------------------
Error 0 detail:
- Error type: Missing logs
- Missing logs from iteration 2 (inclusive) to iteration 4 (inclusive)
- CorruptionId: eyJmcm9tX2l0ZXJhdGlvbiI6MiwidG9faXRlcmF0aW9uIjo0LCJwcmV2aW91c19oYXNoIjoiZGFkNGEwMzMyYTQ1OGZiMzU4OTlmYWQxOTIzYzliNGE1MjZmNzFmZmNmMmU5ZjkxMTExN2I1MTMyMzBkMmFjYyIsImFja25vd2xlZGdlX2Jsb2NrY2hhaW5faWQiOiJhY2tub3dsZWRnZS1lbHByb3h5c2lnbmVkLW5ldGV5ZS1vbmVfd2Vlay0wIn0=
--------------------------------------------------------
Error 1 detail:
- Error type: Wrong Log Hash
- Failed iteration_id: 16
- Expected hash: 34f5bd40d5042ba289d4c5032c75a426306a57e41c0703df4c7698df104f75ed
- Found hash : 593bcd654fd80091105a21f548c1e6a8dd07c80380e72ceeeb1a3e7b126d26bb
- CorruptionId: eyJmcm9tX2l0ZXJhdGlvbiI6MTYsInRvX2l0ZXJhdGlvbiI6MTYsInByZXZpb3VzX2hhc2giOiIwNTE0YmY3YTBmNmRmNmNhMjg1YTIwYTM2OGFiNTA5M2I5NjgxMWZkZWFmMmQ1YThhYjFkOTYwYzgyNDRiNzJlIiwiYWNrbm93bGVkZ2VfYmxvY2tjaGFpbl9pZCI6ImFja25vd2xlZGdlLWVscHJveHlzaWduZWQtbmV0ZXllLW9uZV93ZWVrLTAifQ==
--------------------------------------------------------
--------------------------------------------------------
Each error found is provided with a CorruptionId that uniquely identifies it. The CorruptionId is a base64 encoded JSON that contains data to identify a specific corruption of a blockchain.
If required, an admin can fix a corruption by acknowledging it through the acknowledge command. This command will create an acknoledgement for a specific CorruptionId so that, when the verify is again executed, the linked error in the blockchain will be considered as resolved.
For example, we can acknowledge the first error reported in the above example with:
elastic_blockchain_proxy acknowledge \
--key-file /path/to/secret/key \
--corruption-id=eyJmcm9tX2l0ZXJhdGlvbiI6MiwidG9faXRlcmF0aW9uIjo0LCJwcmV2aW91c19oYXNoIjoiZGFkNGEwMzMyYTQ1OGZiMzU4OTlmYWQxOTIzYzliNGE1MjZmNzFmZmNmMmU5ZjkxMTExN2I1MTMyMzBkMmFjYyIsImFja25vd2xlZGdlX2Jsb2NrY2hhaW5faWQiOiJhY2tub3dsZWRnZS1lbHByb3h5c2lnbmVkLW5ldGV5ZS1vbmVfd2Vlay0wIn0=
The acknowledgement data is persisted in a dedicated Elasticsearch index whose name is
generate from the name of the index to which the corruption belong. For example, if the
corrupted index name is *-*-elproxysigned-neteye-one_week-0-*, then the name of the
acknowledge blockchain will be acknowledge-elproxysigned-neteye-one_week-0.
Warnings and Error Codes¶
The verification process may complete successfully, emit an error or a warning. Errors thrown by El Proxy lead to a failed verification, while warnings may appear also on successful completion.
The following table reports the warnings that could be reported by El Proxy during the verification process, along with the possible causes and actions that can be taken to address the issue.
Warning Code |
Description |
Actions |
|---|---|---|
Untrusted First Iteration No State History |
The first iteration found on the blockchain cannot be trusted because it differs from iteration zero, and the blockchain state history file was not found. Thus, El Proxy cannot confirm that the iterations preceding the one that was found are missing. After the first successful blockchain verification, the blockchain state history file will be created, and the warning will disappear. For more info on this topic, refer to the Verification and Retention Policies section. |
Manually investigate the blockchain to confirm that all previous iterations are expected to be missing and re-run the verification. |
Untrusted First Iteration Insufficient Info |
The first iteration found on the blockchain cannot be trusted because it differs from iteration zero, and the blockchain state history file does not contain enough information to assess the expected first iteration of the blockchain. This warning is thrown when the time between two consecutive verifications exceeds the retention period of the Elasticsearch indices where the blockchain is stored, thus leading to an outdated blockchain state history file. |
Reduce the time between consecutive verifications by increasing the verification frequency. For more info on how to modify the verification frequency, refer to the Verification Setup section. |
Unknown First Iteration |
The blockchain is empty, and the blockchain state history file does not contain any information about the expected first iteration. This warning is thrown on two occasions:
|
Ensure that the blockchain is empty because it is new, and wait for the first log to be indexed before running the verification again. |
Empty Blockchain |
The first expected iteration and all the subsequent iterations were not found in the blockchain.
This warning differs from the
|
Ensure that the absence of newly indexed logs in the blockchain is expected, and wait for some logs to be indexed before running the verification again. |
Retention Policy Not Applied |
The blockchain contains logs that are older than the maximum expected age based on the retention policy of the blockchain. This can happen if the retention policy was not correctly applied to the blockchain or if some logs have been re-indexed after their deletion by the retention policy. |
Ensure that no logs have been re-indexed after their deletion by the retention policy. |
Similarly, the following table reports the errors that could be reported by El Proxy during the verification process, along with the possible causes and actions that can be taken to address the issue.
Error Code |
Description |
Actions |
|---|---|---|
Empty Blockchain Corruption |
The blockchain is empty, and the first expected iteration was not found, leading to a failed verification. El Proxy expected the first iteration based on the blockchain state history file written during the last successful blockchain verification. This error can be thrown if the blockchain state history file is corrupted or if all the logs have been deleted from the blockchain. |
Ensure that the blockchain state history file has not been corrupted, then manually investigate the cause of the missing logs. |
Log Verification Bad Iteration |
The iteration of a log is wrong. This error could be thrown in case one or several consecutive logs are missing, or if one or several logs iterations have been modified. |
Ensure to investigate the problem’s cause and acknowledge the error’s corruption id with the elastic-blockchain-proxy acknowledge command. Then run the verification again. |
Log Verification Wrong Previous Hash |
The previous hash of a log does not match the hash of the previous log. This error can be thrown if the log’s previous hash was modified. |
Same as above. |
Log Verification Wrong Hash |
The hash of a log does not match the hash corresponding to its content. This error can be thrown if the log’s content is modified. |
Same as above. |
Acknowledgement Verification Wrong Previous Hash |
The previous hash of the acknowledgement for a corruption ID does not match the hash of the log right before the corrupted log. This error can be thrown if the previous hash of the acknowledgement has been modified. |
Delete the acknowledgement and run the verification again. |
Acknowledgement Verification Wrong Hash |
The hash of the acknowledgement for a corruption ID does not match the expected hash. This error can be thrown if the acknowledgement content has been modified. |
Same as above. |